
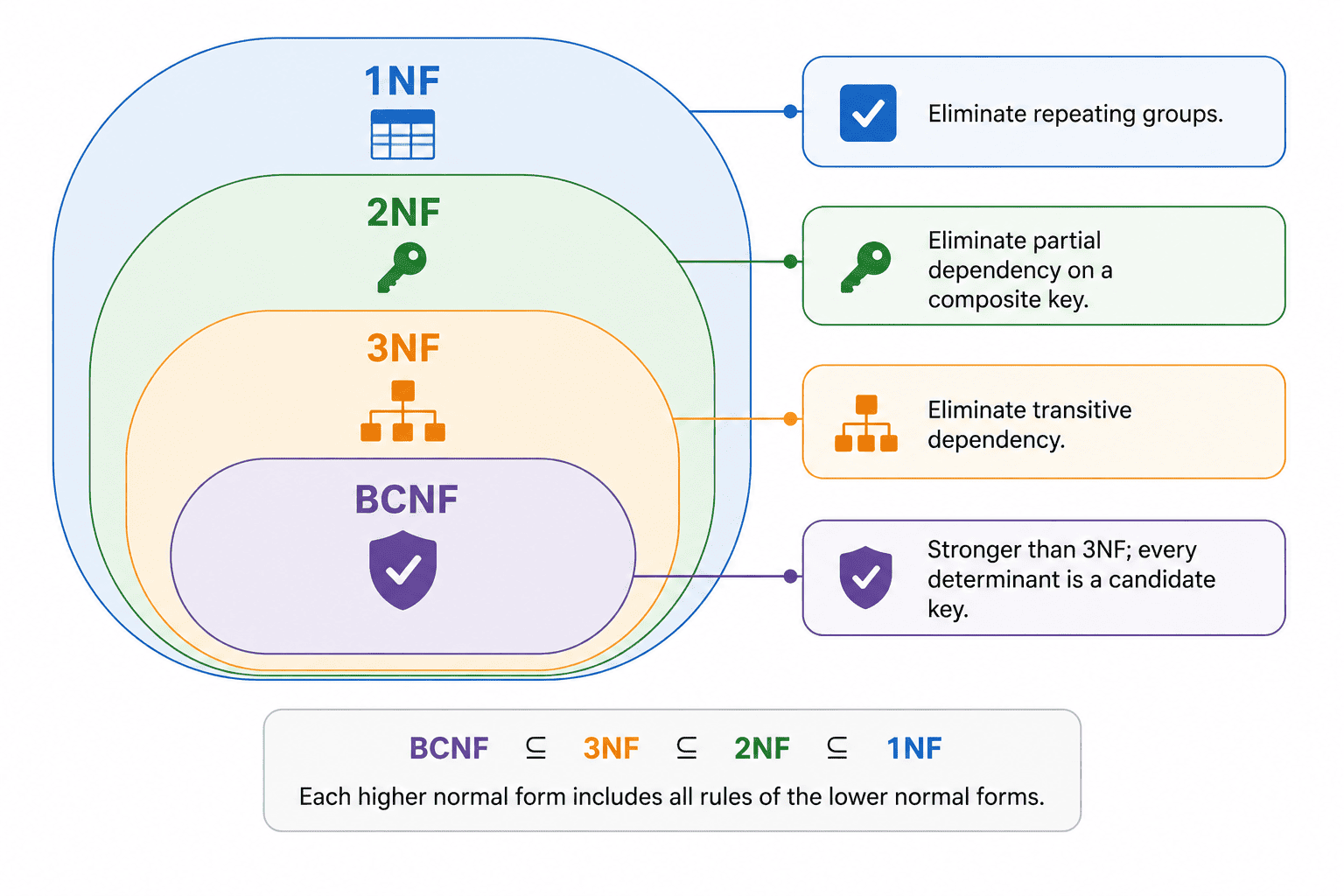
Database Normalization
Normalization is the systematic process of organizing a database schema to reduce redundancy and maintain data integrity. It is achieved through step-by-step 'lossless decomposition'—breaking down large, poorly designed tables into smaller, well-structured ones without losing any information.
When a database is not normalized, data is repeated unnecessarily. This redundancy inevitably leads to Anomalies, which are critical errors that occur when you try to insert, update, or delete data.
The Three Deadly Anomalies
- Insertion Anomaly: You cannot insert a new piece of data because it requires unrelated data to exist first. For example, if a table stores both Course and Student data together, you cannot create a new Course until at least one Student enrolls in it!
- Update Anomaly: Because data is duplicated across multiple rows, changing a single fact (like a professor's phone number) requires updating every single row they appear in. If you miss even one row, your database becomes inconsistent and corrupt.
- Deletion Anomaly: Deleting one piece of data accidentally wipes out unrelated data. For example, deleting the only student enrolled in a course might completely erase the course's existence from the database.
First Normal Form (1NF): Atomicity
The Golden Rule of 1NF: Every attribute (column) in a relation must contain only atomic, single-valued elements.
You cannot have nested groups, lists, or comma-separated strings inside a single cell.
Why is violating 1NF bad?
Imagine a Student table where the Phone_Numbers column contains multiple phone numbers separated by commas (e.g., '123-4567, 987-6543').
If you need to search for the student who owns the number '987-6543', you cannot do a simple SQL WHERE Phone = '987-6543'. You are forced to do expensive substring string-matching like LIKE '%987-6543%'. It also makes joining tables based on phone numbers completely impossible.
| Student_ID | Name | Phone_Numbers |
|---|---|---|
| 101 | Alice | 123-4567, 987-6543 |
| 102 | Bob | 555-1234 |
The Solution: To achieve 1NF, we must split these multi-valued attributes. We extract the phone numbers into a separate child table that references the parent table.
| Student_ID | Name |
|---|---|
| 101 | Alice |
| 102 | Bob |
| Student_ID | Phone |
|---|---|
| 101 | 123-4567 |
| 101 | 987-6543 |
| 102 | 555-1234 |
Second Normal Form (2NF): No Partial Dependencies
The Golden Rule of 2NF: The table must be in 1NF, and it must contain no partial dependencies.
A partial dependency can *only* occur if your table has a Composite Primary Key (a primary key made of two or more columns). It happens when a non-key column depends on only *part* of that composite primary key, rather than the entire key.
Why is violating 2NF bad?
Consider an Enrollment table tracking which student is taking which course. The Primary Key must be the combination of {Student_ID, Course_ID} because one student takes many courses, and one course has many students.
However, the column Course_Name depends ONLY on Course_ID. It has absolutely nothing to do with the Student_ID.
The Anomaly: If 100 students enroll in 'Databases', the string 'Databases' is written into the database 100 times. If the course name changes to 'Advanced Databases', you have to update 100 rows. If you miss one, your database is corrupted (Update Anomaly)!
| Student_ID | Course_ID | Course_Name |
|---|---|---|
| 101 | CS101 | Databases |
| 102 | CS101 | Databases |
The Solution: We decompose the table. Everything that depends ONLY on Course_ID gets moved into its own Course table.
| Student_ID | Course_ID |
|---|---|
| 101 | CS101 |
| 102 | CS101 |
| Course_ID | Course_Name |
|---|---|
| CS101 | Databases |
Third Normal Form (3NF): No Transitive Dependencies
The Golden Rule of 3NF: The table must be in 2NF, and it must contain no transitive dependencies.
A transitive dependency occurs when a non-key column depends on another non-key column, which in turn depends on the primary key. Put simply: A → B and B → C. Therefore, C is transitively dependent on the primary key A through B.
Why is violating 3NF bad?
Consider an Employee table where the Primary Key is Emp_ID. We also store the employee's Dept_ID and the Dept_Location.
The Dept_Location depends entirely on the Dept_ID (not the employee!). But Dept_ID depends on Emp_ID.
The Anomaly: If the Sales Department (D1) moves from New York to Chicago, we have to update the Dept_Location column for every single employee in the Sales department. Furthermore, if a new department is created but has no employees yet, we cannot store its location (Insertion Anomaly).
| Emp_ID | Dept_ID | Dept_Location |
|---|---|---|
| 1 | D1 | New York |
| 2 | D1 | New York |
The Solution: We decompose the table to break the chain. The intermediate dependency (Dept_ID) becomes the primary key of a new Department table.
| Emp_ID | Dept_ID |
|---|---|
| 1 | D1 |
| 2 | D1 |
| Dept_ID | Dept_Location |
|---|---|
| D1 | New York |
Boyce-Codd Normal Form (BCNF): The Stricter 3NF
The Golden Rule of BCNF: For every non-trivial functional dependency α → β, the determinant (α) MUST be a Super Key.
BCNF is a stricter version of 3NF. It handles very specific edge cases where a table has overlapping candidate keys.
Why is violating BCNF bad?
Consider a Booking(Student_ID, Course_ID, Professor_ID) table.
Rule 1: A student has exactly 1 professor per course. So, the Primary Key is {Student_ID, Course_ID}.
Rule 2: A professor only teaches one specific course. This means Professor_ID → Course_ID.
The Violation: We have a dependency Professor_ID → Course_ID. But is Professor_ID a super key? No! A professor might teach multiple students, so their ID alone does not uniquely identify a row. Because a determinant is NOT a super key, it violates BCNF.
| Student_ID | Course_ID | Professor_ID |
|---|---|---|
| 101 | CS101 | P1 |
| 102 | CS101 | P1 |
The Solution: We decompose it so that Professor_ID becomes a proper primary key in its own table.
| Student_ID | Professor_ID |
|---|---|
| 101 | P1 |
| 102 | P1 |
| Professor_ID | Course_ID |
|---|---|
| P1 | CS101 |
Placement Takeaways
Normalization is one of the most frequently tested topics in DBMS interviews. You must be able to instantly spot partial and transitive dependencies.
Fill in the Blank
Sort the Concepts
Drag the dependency elimination rule into its correct Normal Form bucket: