
Database Foundations & Introduction
A database is an organized, logically cohesive repository of persistent, related data designed to model real-world systems. Unlike simple data files, a database is built with a specific purpose and represents a clear semantic domain.
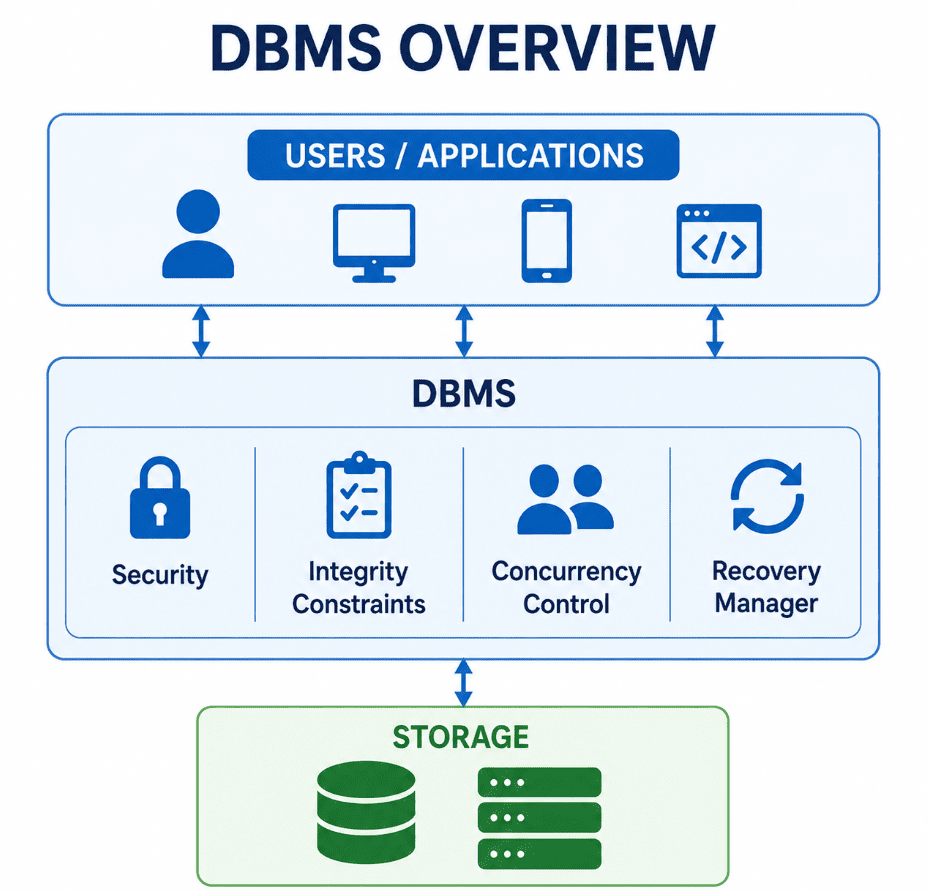
Why do we need a DBMS? (The File System Problem)
To understand the architecture of modern relational systems, one must evaluate the limitations of legacy file-processing frameworks. In legacy setups, data resided in isolated physical files with specialized formats. This design made application programs highly dependent on the physical layout of the files, which created several structural and operational challenges:
1. Redundancy and Inconsistency: Because different departments within an organization maintain separate files, the same information is often duplicated across the storage system. When a customer's address changes, updating it in one file but not another leads to inconsistent records.
2. Data Isolation: Information is scattered across multiple files with different formats. This makes it difficult to write new applications or execute ad-hoc queries.
3. Integrity Problems: Enforcing data integrity is challenging because validation rules are hardcoded directly into application programs. If a business rule changes, developers must update every program that accesses the data.
4. Atomicity Failures: During system crashes, a multi-step update (such as a bank transfer) can fail midway, leaving the data partially modified and corrupt.
5. Concurrent Access & Security: File systems lack the mechanisms needed for concurrent access and granular security control. This can lead to lost updates when multiple users modify a file simultaneously, and it makes it difficult to restrict access to specific sensitive columns.
File-Processing System vs DBMS
Modern database management systems address these limitations by decoupling physical storage from logical access. Here is how they compare:
| Operational Dimension | File-Processing Limitations | DBMS Structural Solutions |
|---|---|---|
| Data Redundancy | High; identical data is duplicated across independent files. | Minimal; data is stored in a centralized, normalized schema. |
| Data Consistency | Low; independent updates lead to conflicting records. | High; single updates propagate to all logical views of the data. |
| Structural Dependency | High; changes to file layouts require rewriting applications. | Low; logical abstraction isolates programs from physical storage changes. |
| Data Access | Hard; requires writing custom code to parse individual files. | Easy; declarative query languages allow ad-hoc data retrieval. |
| Integrity Enforcement | Hardcoded; validation rules must be written into each program. | Declarative; rules are defined in the schema and enforced by the engine. |
| Atomicity & Recovery | Manual; program failures can leave data partially updated. | Automatic; transaction managers roll back incomplete updates. |
| Concurrency Control | Absent; simultaneous updates can overwrite/corrupt records. | Multi-user; locking and serialization protect shared data. |
| Security Controls | Coarse; access control is limited to OS file permissions. | Granular; permissions can be restricted down to columns and rows. |
Placement Takeaways
When interviewing for software engineering roles, interviewers often test your fundamental understanding of *why* databases exist before diving into SQL queries or normalization.
- Data Independence: The ability to modify a schema definition in one level without affecting a schema definition in the next higher level. It is divided into Logical and Physical Data Independence.
- ACID Properties: Atomicity, Consistency, Isolation, and Durability. This is arguably the most frequently asked theoretical DBMS question. You must know how a DBMS ensures these properties during transactions.
- Concurrency Control: How the DBMS handles multiple users reading and writing to the database at the exact same time without data corruption (Locks, Timestamps, etc.).