Why Understanding Algorithm is More critical Than Ever
In today’s tech-driven world, mastering Data Structures and Algorithms (DSA) has become a fundamental skill for any aspiring software developer or engineer. Whether you’re preparing for coding interviews, competitive programming, or solving real-world problems, DSA forms the backbone of efficient and scalable solutions. In fact, the ability to understand and analyze the algorithm you write is often more critical than just solving a problem. Why? Because it’s not just about finding a solution — it’s about finding the most optimal one.
As companies handle growing volumes of data, the efficiency of algorithms in terms of time and space complexity is crucial. That’s why optimizing code performance is often more important than just solving the problem.
So This Could Be the Right One to Know Everything
What is Time Complexity?
Time complexity is a way to describe how the runtime of an algorithm increases as the input size grows. In simple terms, it tells us how much time an algorithm takes to run depending on the amount of data we give it.
Analogy: Think of it like ordering at a fast-food restaurant. If there’s only one person ahead of you, you’ll get your food quickly. But if there’s a long line of 50 people, it will take much longer to get your food. The length of the line represents the size of the input, and the time it takes to get your order is the time complexity. This illustrates the concept of time complexity: as the input (number of people) grows, the time required for the algorithm here:(order) typically increases as will.
Common Misconceptions About Time Complexity
While time complexity is a powerful tool for analyzing algorithms, there are several misconceptions that beginners often have:
- “If it works, it’s good enough”: Many new developers assume that if their code produces the correct output, it’s a good solution. However, correctness alone isn’t sufficient. For example, a brute-force solution might work for small inputs but become impractically slow for large datasets.
- “Fast code is always better”: Just because an algorithm runs quickly for small inputs doesn’t mean it will scale well. For instance, an O(n²) algorithm might seem fast when n is 10, but when n grows to 1,000, the runtime could skyrocket.
- “Time taken by the code execution is the same as time complexity”: Many beginners mistakenly believe that the actual time taken for code execution directly reflects its time complexity. However, this is not the case. Various factors, such as CPU speed and system architecture, can affect execution time, making it distinct from the theoretical measure of time complexity.
Understanding time complexity and recognizing common misconceptions are essential for developing efficient algorithms. By grasping these concepts, developers can create solutions that not only work correctly but also perform well under varying input sizes.
Steps to Compute Time Complexity
When computing time complexity, especially as a beginner, there are three key principles to follow:
1. Always Consider the Worst-Case Scenario: Worst case refers to the situation where the algorithm performs the maximum number of steps. This is crucial because it gives you the upper bound of how long an algorithm could take, even in the most challenging cases.
- For example, if you’re searching for an element in a list, the worst case is when the element is at the very end (or not found at all), requiring the algorithm to check every single item.
- Why worst case? It ensures we’re prepared for the most time-consuming situation, which is essential for evaluating efficiency.
2. Avoid ConstantsAvoiding constants: means we focus on how the algorithm scales with large inputs rather than small fixed values. Constants (like +1, +2, or multiplying by a small number) don’t significantly impact performance when input size becomes large.
- Example: Consider an algorithm that takes 2n + 3 steps. While “2” and “3” are constants, they matter very little when n becomes extremely large, so we simplify the complexity to just O(n).
- Relating it to the analogy: If you’re waiting in line with 50 people, whether you’re delayed by 2 or 3 extra seconds doesn’t matter much — it’s the total number of people (input size) that determines how long you’ll wait.
3. Avoid Lower ValuesWhen computing time complexity, we focus on large input sizes, as that’s when the efficiency of an algorithm really matters. Small inputs might not reveal the true scaling behavior of your code.
- For example, an algorithm with complexity O(n²) might seem fast for small inputs like n = 5, but as n grows (e.g., to 1,000), the difference between O(n) and O(n²) becomes dramatic.
- Relating it to the analogy: If only 3 people are ahead of you, the time complexity might not seem like a concern. But when there are 50 or 100 people in line, the way the algorithm handles larger inputs is what makes a real difference.
Step 2 helps you simplify time complexity by ignoring small constants in the expression.
Step 3 encourages you to analyze the algorithm’s performance with large input sizes rather than focusing on small, trivial cases.
Best, Average, and Worst Case in Algorithms
When analyzing algorithms, we consider three possible scenarios for performance and three notations:
Big O, omega, theta
- Best Case (Ω Notation): This is when an algorithm performs its fastest. For example, in a linear search, if the target element is the first in the list, the search ends in constant time, which is Ω(1).
- Average Case (Θ Notation): This is the expected performance, typically when inputs are random. For instance, finding an element in the middle of a list takes around half the time, making it Θ(n/2), but simplified to Θ(n).
- Worst Case (O Notation): This scenario assumes the most time-consuming input, like searching for the last element or not finding it at all. This makes the time complexity O(n) in linear search.
Why Do We Use Big O? Worst-Case Guarantees: Big O ensures that no matter the input, the algorithm won’t perform worse than expected.
Scalability: Focusing on worst-case scenarios helps ensure that your algorithm can handle large and unpredictable datasets effectively.
Practicality: While average and best-case scenarios (Θ and Ω) are useful, they aren’t always reliable in real-world applications, where ensuring worst-case performance is crucial.
Types of Time Complexities
Time complexity helps us understand how the runtime of an algorithm grows with input size. The most common types of time complexities, in order of their efficiency from best to worst, are:
- Constant Time – O(1)
- Logarithmic Time – O(log n)
- Linear Time – O(n)
- Linearithmic Time – O(n log n)
- Quadratic Time – O(n²)
- Exponential Time – O(2ⁿ)
1. Constant Time – O(1)
- Definition: The runtime of the algorithm does not change with the size of the input. It always takes the same amount of time, no matter how large or small the input is.
- Example: Accessing an element in an array by its index.
int getFirstElement(int arr[], int n){
//Always takes the constant time to access the first element.
return arr[0];
}
No matter how large the array is, accessing the first element always takes constant time.
2. Logarithmic Time – O(log n)
- Definition: Logarithmic time complexity occurs when an algorithm’s runtime increases much more slowly than the input size. This typically happens when the algorithm repeatedly divides the input size in half to find a solution.
- Mathematical Insight: For an input size of n, binary search completes in log₂(n) steps. Searching through 16 elements takes 4 steps, and for 1,000 elements, it takes around 10 steps, which is significantly faster than linear search.
why is it called Logarithmic?
The number of operations grows logarithmically because the problem space is reduced exponentially with each step. For example, binary search splits the search space in half at every step.
Real-World Analogy
Imagine finding a word in a dictionary. Instead of checking every word one by one, you flip to the middle, decide if the word is before or after, and then repeat by halving the search space. This is why binary search operates in O(log n) time — a far more efficient approach for large datasets.
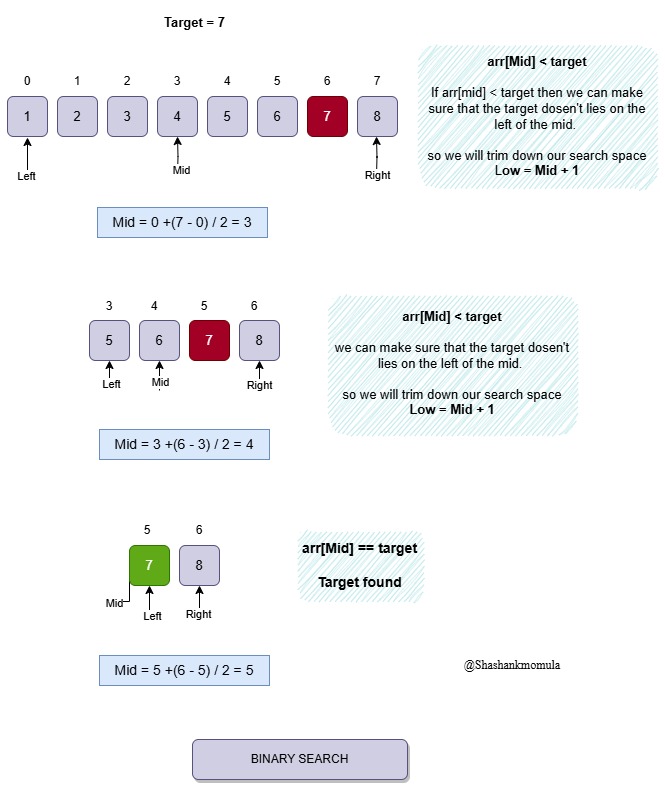
Eample: Binary Search Algorithm
Target : 7
int binarySearch(int arr[], int n, int target){
int left = 0, right = n-1; //O(1)
while(left<=right){
// O(log n): The loops run logarithmically based on the size of input
int mid = left+(right-left)/2; //O(1)
if(arr[mid] == target) return mid;
else if(arr[mid] < target) left = mid+1;
else right = mid-1;
}
return -1; //O(1)
}
3. Linear Time – O(n)
- Definition: Linear time complexity, denoted O(n), means that the runtime grows directly in proportion to the input size. if the input doubles, the time it takes to complete the task also doubles.
Example: Linear Search Algorithm
A linear search algorithm is a classic example of this. It checks each element in an array one by one until it finds the target value.
int linearSearch(int arr[], int n, int target){
for(int i=0; i<n; i++){ //O(n) Iterating through all elements
if(arr[i] == target){ // O(1) checking the current element
return i;
}
}
return -1; //O(1) if target is not found
}
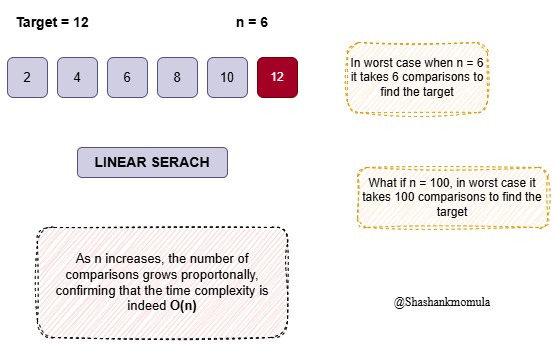
Why is it O(n)?
In the worst case, the algorithm checks all n elements before finding the target or concluding it’s not present. Thus, the number of operations increases linearly with the input size.
Real-World Analogy:
Imagine searching for a book in a library, checking each book one by one. If there are 100 books, you might check all 100; if there are 1,000 books, it could take up to 1,000 checks. This reflects the linear growth of time with the input size.
4. Linearithmic Time – O(n log n)
- Definition: Linearithmic time complexity, denoted as O(n log n), means the runtime grows in proportion to n times the logarithm of n. This complexity often shows up in efficient algorithms that involve both dividing a problem and processing each part. You may wonder: why n, why log n, and how do these combine? Let’s explore with a real-world analogy for better understanding.
Real-World Analogy for O(n log n) – Sorting Jumbled ID Cards of a Class
Imagine you have 50 jumbled ID cards, and your task is to arrange them in order by student number. Sorting all 50 cards at once would be overwhelming, so you decide to use a divide-and-conquer approach, similar to how merge sort works.
Dividing the ID Cards – O(log n):
First, you repeatedly divide the cards into smaller groups. Split 50 cards into two piles of 25, then split those again, and so on until you have single cards.
Each time you halve the pile, you’re reducing the problem size, taking log n steps. For example:
50 cards → 25 cards → 12 cards → 6 → 3 → 1.
This step takes O(log n) because you’re dividing the cards in half until you can’t divide anymore.
Sorting and Merging – O(n):
Now that each card is a single pile, you start merging.
At each step, you compare and combine two piles of cards in the correct order. To merge two piles, you need to touch each card once, making this step O(n), where n is the total number of cards.
Why Does This Process Take O(n log n)?
O(log n) comes from the repeated division of the cards into smaller groups.
O(n) comes from the merging process, where you sort and combine each card back together.
In short, you’re dividing the problem into smaller pieces in log n steps, and for each division, you’re sorting all the cards, making the overall complexity O(n log n).
Now let’s look at how this works in an actual algorithm with the merge sort code:
void mergeSort(int arr[], int l, int r){
if(l<r){
int m = l+(r-l)/2; // Find the middle
mergeSort(arr,l,m); // Sort the first half
mergeSort(arr,m+1,r); // Sort the second half
merge(arr,l,m,r); // Merge the sorted halves
}
}
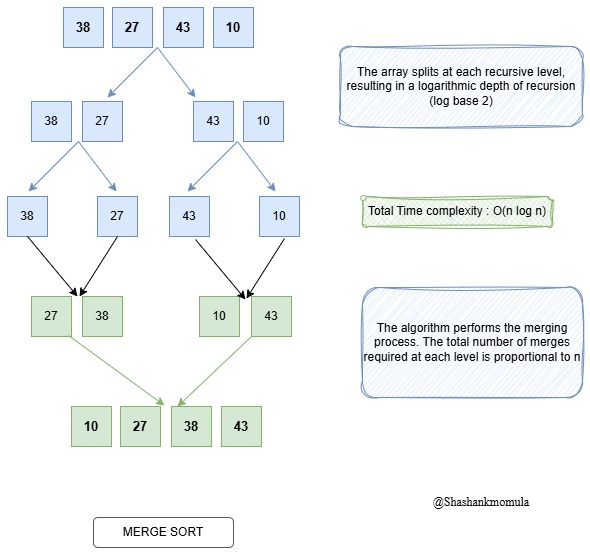
When you first look at the merge sort code, you might wonder, What is mergeSort()? What is merge()? Don’t worry! It’s just a sorting algorithm that breaks the array into smaller parts, sorts them, and then merges them back together.
To fully understand how this works, take a moment to explore it for yourself. Here’s a simple breakdown:
- mergeSort() is the function that splits the array into smaller parts until each part is a single element.
- merge() is the function that combines those single elements (or smaller arrays) back together in sorted order.
Once you start diving deeper into it, you’ll find merge sort to be an elegant and efficient way of sorting!
Give it a try, and you’ll see it’s not as scary as it looks!
5. Quadratic Time – O(n^2)
- Definition: Quadratic time complexity, denoted as O(n^2), means that the runtime grows in proportion to the square of the input size. This is common in algorithms where each element needs to be compared or processed with every other element, often leading to nested loops.
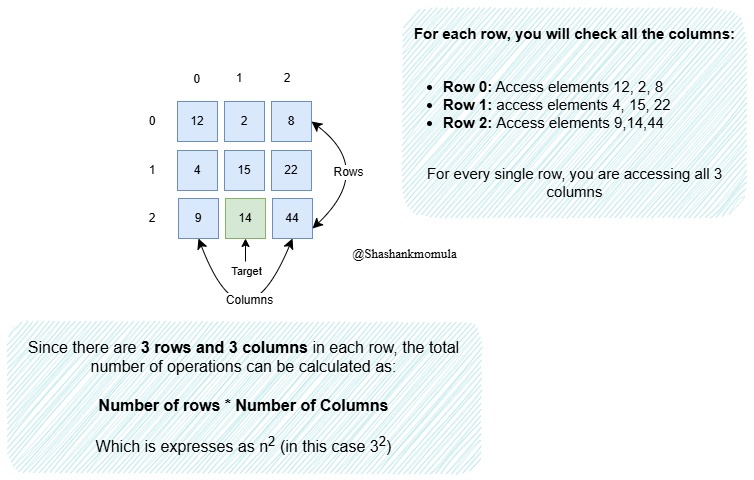
Example: Accessing Elements in an n×n Matrix(2D)
Imagine you have an n×n grid (like a matrix), and you need to perform some operation on each cell in the grid or you need to find a target element, one by one. Since there are n rows and n columns, this results in n×n = n^2 operations in total, as every element in each row is accessed once per column.
bool findElement(int matrix[3][3], int target){
for(int i=0;i<3;i++){ //outer loops iterates over rows
for(int j=0;j<3;j++){ //inner loop iterates over columns
if(matrix[i][j] == target){
return true;
}
}
return false;
}
6. Exponential Time Complexity – O(2^n)
Exponential time complexity, denoted as O(2^n), describes an algorithm where the runtime doubles with each additional input element. This complexity is among the slowest and quickly becomes unfeasible for even moderately large inputs, often appearing in recursive algorithms that branch into multiple subproblems — such as the naive recursive solution to the Fibonacci sequence.
Example: Calculating the Fibonacci Sequence (Recursive Approach)
In the Fibonacci sequence, each number is the sum of the previous two. A simple recursive approach to calculate this follows:
int fibonacci(int n){
if(n<=1)return n;
return fibonacci(n-1)+fibonacci(n-2);
}
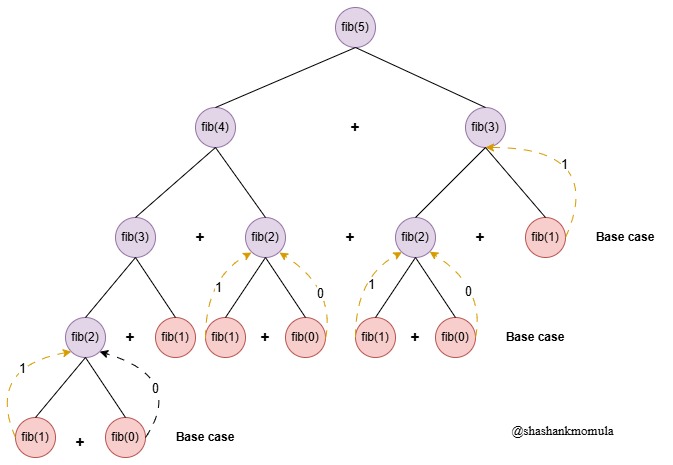
In this code, each call to fibonacci(n) branches into two further calls for fibonacci(n-1) and fibonacci(n-2), resulting in a branching factor of 2. For an input size of n, the total number of recursive calls grows roughly as 2^n.
Why Exponential?
Each recursive call leads to two more, making the process double with every increase in input size. For example, calculating fibonacci(5) is manageable, but fibonacci(40) would require over a billion calls due to the exponential growth.
Real-World Analogy: Folding a Piece of Paper
Imagine folding a piece of paper in half. The thickness doubles with each fold: 2 layers on the 1st fold, 4 on the 2nd, 8 on the 3rd, and so on. After 20 folds, the paper would have over a million layers! Similarly, exponential algorithms quickly become impractical, as their growth doubles with every additional input. Just as you can only fold a paper so many times, exponential algorithms rapidly become unmanageable with even small increases in input size.
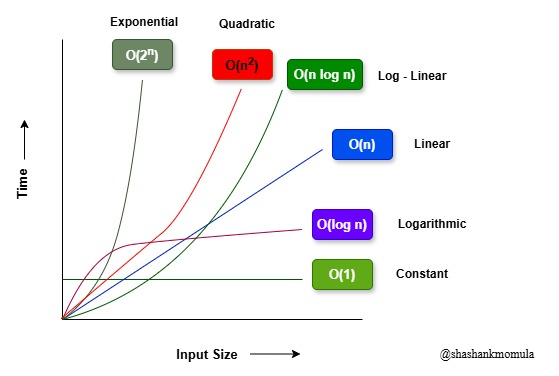
- O(1) – Constant Time: The time remains constant regardless of the input size, making it the fastest and most efficient time complexity. Examples include accessing an element by index in an array.
- O(log n) – Logarithmic Time: As the input size increases, the time grows very slowly. This is often seen in algorithms that repeatedly halve the input, like binary search.
- O(n) – Linear Time: The time complexity grows linearly with the input size. For example, a single loop iterating over n elements takes O(n) time.
- O(n^2) – Quadratic Time: The time complexity grows quadratically, often seen in algorithms with nested loops. Sorting algorithms like bubble sort have this complexity.
- O(2^n) – Exponential Time: The time grows extremely fast as n increases, making it impractical for large inputs. Recursive algorithms that solve all subsets, such as solving the traveling salesman problem, have this complexity.
From this comparison, O(1) and O(log n) are the most efficient, while O(n^2) and O(2^n) should generally be avoided for large inputs due to their steep growth rate. Choosing the right algorithm with a lower time complexity significantly impacts performance, especially as the input size grows.
What is Space complexity?
Space complexity measures the extra memory an algorithm needs to run efficiently, calculated as a function of the input size. It helps us estimate how much storage an algorithm will use by analyzing the memory needed for components like variables, data structures, function calls, and temporary storage.
Components of Space Complexity
Fixed Memory Requirements:
- Constants: Fixed values like configuration settings that do not change with input size.
- Primitive Variables: Basic counters or indexes, which remain constant regardless of input.
Variable Memory Requirements:
- Data Structures: Memory for structures like arrays or lists, which grow with the input.
- Function Call Stack: For recursive algorithms, each call adds to the stack until all calls are resolved.
- Temporary Storage: Memory for intermediate results, such as buffers or temporary arrays.
Real-World Analogy: Packing a Suitcase
Imagine packing a suitcase:
- Essentials vs. Extras: Essentials (core memory) are always needed, while extras represent additional memory for optional tasks.
- Efficient Packing: Like minimal packing, using only necessary memory keeps the algorithm efficient.
- Limited Capacity: Just as a suitcase has limited space, computers have finite memory; using memory efficiently is crucial.
Example: Reversing an Array
To reverse an array, a naive approach is to create a new array to store elements in reverse order, which requires extra memory proportional to the input size, giving an O(n) space complexity. For large inputs, this approach could be inefficient due to increased memory usage.
In summary, space complexity is essential for understanding and minimizing the memory requirements of an algorithm, particularly in environments where memory is limited.
- O(1) – Constant Space Complexity: The algorithm uses a fixed amount of memory regardless of the input size. Examples include algorithms that only use a few variables, like swapping two numbers.
- O(n) – Linear Space Complexity: The memory usage grows linearly with the input size. For example, storing n elements in an array or a list requires O(n) space.
- O(n²) – Quadratic Space Complexity: The space required increases quadratically with the input size, such as a 2D array of size n x n. This type of complexity can quickly become inefficient as input size grows.
Conclusion
Optimizing both time and space complexity is crucial for building efficient algorithms. By understanding and selecting the right time and space complexity, you can make your algorithms faster and more memory-efficient, leading to smoother, more scalable applications.
Optimizing your code is like sharpening a tool — the sharper it is, the better it performs. Aim for efficiency, and let your algorithms do more with less.

1,221 Comments
Really enjoyed this article post.Thanks Again.
does rx pharmacy coupons work pharmacy technician requirements in canada
An interesting discussion is worth comment. I assume that you ought to write a lot more on this subject, it may not be a forbidden topic however normally people are not enough to talk on such topics. To the next. Cheers
Awesome things here. I am very happy to see your post. Thanks a lot and I’m looking forward to touch you. Will you kindly drop me a mail?
ivermectin walmart ivermectin pour-on tractor supply
does ivermectin kill scabies ivermectin for scabies dosage
Thanks for the blog.Really thank you! Cool.
wow, awesome post.Really thank you! Fantastic.
Thanks-a-mundo for the article post.Thanks Again. Much obliged.
Very informative blog article.Really looking forward to read more. Great.
Thanks-a-mundo for the article post.Really looking forward to read more. Want more.
Great artical, had no problems printing this page either.
Have you ever heard of second life (sl for short). It is essentially a online game where you can do anything you want. SL is literally my second life (pun intended lol). If you would like to see more you can see these sl authors and blogs
La disfunción eréctil es un problema que afecta a millones de hombres en todo el mundo, y que tiene una gran repercusión en su calidad de vida y en la de sus parejas.
There is perceptibly a lot to identify about this. I think you made certain nice points in features also.
These are genuinely wonderful ideas in about blogging.You have touched some pleasant factors here. Any way keep up wrinting.
Thank you ever so for you blog article. Great.
Great blog article. Will read on…
A motivating discussion is worth comment. I do believe that you need to write more on this issue, it might not be a taboo matter but typically people don’t discuss such issues. To the next! Many thanks!!
Appreciate you sharing, great article post.Really looking forward to read more. Really Great.
Im obliged for the post.Thanks Again. Keep writing.
It’s actually a great and useful piece of info. I am glad that you shared this useful information with us. Please stay us up to date like this. Thanks for sharing.
Hey There. I found your blog using msn. This is a very well written article. I will make sure to bookmark it and return to read more of your useful info. Thanks for the post. I will certainly comeback.
biden hydroxychloroquine chloroquine primaquine
I value the post.Thanks Again. Keep writing.
Good day! I simply wish to offer you a big thumbs up for your great information you have got here on this post. I will be coming back to your blog for more soon.
Oh my goodness! Awesome article dude! Many thanks, However I am having difficulties with your RSS. I donít know why I cannot join it. Is there anybody having identical RSS issues? Anyone that knows the solution can you kindly respond? Thanks!!
I truly appreciate this article post.Much thanks again. Awesome.
top farmacia online: Farma Prodotti – Farmacia online piГ№ conveniente
farmacia online senza ricetta
Oh my goodness! Incredible article dude! Thanks, However I am having difficulties with your RSS. I donít understand why I can’t join it. Is there anyone else getting similar RSS issues? Anyone who knows the solution will you kindly respond? Thanx!!
Really appreciate you sharing this article.Much thanks again. Really Great.
Some genuinely fantastic information, Gladiola I found this.
viagra online consegna rapida [url=https://farmasilditaly.com/#]viagra senza ricetta[/url] viagra pfizer 25mg prezzo
Los juegos en vivo ofrecen emociГіn adicional.: jugabet – jugabet chile
Many casinos offer luxurious amenities and services. http://phmacao.life/# Resorts provide both gaming and relaxation options.
https://winchile.pro/# La competencia entre casinos beneficia a los jugadores.
Gambling regulations are strictly enforced in casinos.
Los casinos son lugares de reuniГіn social.: jugabet chile – jugabet
jugabet casino [url=http://jugabet.xyz/#]jugabet.xyz[/url] Las promociones atraen nuevos jugadores diariamente.
https://jugabet.xyz/# Las mГЎquinas tragamonedas tienen temГЎticas diversas.
The poker community is very active here.
Gambling can be a social activity here.: taya777 – taya777 register login
Casinos offer delicious dining options on-site.: taya777 register login – taya777 app
https://taya365.art/# Responsible gaming initiatives are promoted actively.
Many casinos offer luxurious amenities and services.
Casino promotions draw in new players frequently. https://phtaya.tech/# Most casinos offer convenient transportation options.
taya365 login [url=https://taya365.art/#]taya365[/url] Slot machines feature various exciting themes.
http://jugabet.xyz/# Algunos casinos tienen programas de recompensas.
Responsible gaming initiatives are promoted actively.
Casino visits are a popular tourist attraction. http://taya365.art/# Many casinos host charity events and fundraisers.
https://jugabet.xyz/# Los jugadores deben jugar con responsabilidad.
Some casinos have luxurious spa facilities.
The gaming floors are always bustling with excitement. https://taya777.icu/# Casinos offer delicious dining options on-site.
taya365 [url=http://taya365.art/#]taya365[/url] Many casinos provide shuttle services for guests.
Some casinos have luxurious spa facilities.: phmacao com login – phmacao casino
http://phtaya.tech/# Casino promotions draw in new players frequently.
Promotions are advertised through social media channels.
https://phmacao.life/# The casino experience is memorable and unique.
Casinos often host special holiday promotions.
Slot machines attract players with big jackpots. https://taya777.icu/# Casinos offer delicious dining options on-site.
Los casinos reciben turistas de todo el mundo.: jugabet chile – jugabet chile
https://phtaya.tech/# Gambling regulations are strictly enforced in casinos.
Entertainment shows are common in casinos.
winchile [url=http://winchile.pro/#]winchile.pro[/url] Las reservas en lГnea son fГЎciles y rГЎpidas.
Loyalty programs reward regular customers generously. http://taya777.icu/# Players must be at least 21 years old.
The Philippines has several world-class integrated resorts.: phtaya.tech – phtaya.tech
https://phtaya.tech/# Gaming regulations are overseen by PAGCOR.
Gambling regulations are strictly enforced in casinos.
Los croupiers son amables y profesionales.: winchile – winchile
Live dealer games enhance the casino experience. http://taya777.icu/# The Philippines has a vibrant nightlife scene.
Resorts provide both gaming and relaxation options.: taya365 – taya365 com login
https://taya365.art/# Resorts provide both gaming and relaxation options.
The Philippines has a vibrant nightlife scene.
Gambling regulations are strictly enforced in casinos. https://taya365.art/# The Philippines has a vibrant nightlife scene.
https://phtaya.tech/# Some casinos have luxurious spa facilities.
Security measures ensure a safe environment.
The casino atmosphere is thrilling and energetic.: phmacao – phmacao casino
https://taya777.icu/# Poker rooms host exciting tournaments regularly.
Cashless gaming options are becoming popular.
Security measures ensure a safe environment. http://phtaya.tech/# The casino experience is memorable and unique.
Los jugadores deben jugar con responsabilidad.: winchile – win chile
https://taya365.art/# Many casinos host charity events and fundraisers.
Slot machines feature various exciting themes.
Manila is home to many large casinos.: taya777 – taya777
Responsible gaming initiatives are promoted actively.: phmacao casino – phmacao club
taya365 [url=http://taya365.art/#]taya365[/url] Slot tournaments create friendly competitions among players.
Las redes sociales promocionan eventos de casinos.: winchile.pro – win chile
http://winchile.pro/# La adrenalina es parte del juego.
Cashless gaming options are becoming popular.
Las apuestas deportivas tambiГ©n son populares.: jugabet chile – jugabet.xyz
http://phtaya.tech/# Most casinos offer convenient transportation options.
Resorts provide both gaming and relaxation options.
Hay reglas especГficas para cada juego.: win chile – win chile
taya365 com login [url=https://taya365.art/#]taya365.art[/url] Players enjoy both fun and excitement in casinos.
http://winchile.pro/# La iluminaciГіn crea un ambiente vibrante.
Entertainment shows are common in casinos.
Many casinos provide shuttle services for guests.: phtaya.tech – phtaya casino
https://phmacao.life/# Visitors come from around the world to play.
The casino industry supports local economies significantly.
La iluminaciГіn crea un ambiente vibrante.: jugabet chile – jugabet.xyz
The gaming floors are always bustling with excitement.: taya777 app – taya777 login
taya777 app [url=https://taya777.icu/#]taya777 login[/url] Players enjoy a variety of table games.
Slot machines feature various exciting themes.: phtaya – phtaya login
Casino visits are a popular tourist attraction.: taya777 app – taya777 login
http://taya777.icu/# Slot machines attract players with big jackpots.
Many casinos provide shuttle services for guests.
my family essay writing – paper writing online help with term paper
http://taya777.icu/# Casinos often host special holiday promotions.
Promotions are advertised through social media channels.
The Philippines has a vibrant nightlife scene. http://phmacao.life/# Casino visits are a popular tourist attraction.
Casino promotions draw in new players frequently.: phmacao com – phmacao com login
The casino experience is memorable and unique.: taya777.icu – taya777 app
https://taya777.icu/# Responsible gaming initiatives are promoted actively.
Promotions are advertised through social media channels.
Las reservas en lГnea son fГЎciles y rГЎpidas.: winchile casino – winchile.pro
phtaya [url=https://phtaya.tech/#]phtaya[/url] The Philippines offers a rich gaming culture.
http://taya777.icu/# Gambling regulations are strictly enforced in casinos.
A variety of gaming options cater to everyone.
best india pharmacy: buy prescription drugs from india – MegaIndiaPharm
online pharmacy delivery usa: Best online pharmacy – online pharmacy delivery usa
cheapest pharmacy to fill prescriptions with insurance http://xxlmexicanpharm.com/# xxl mexican pharm
rx pharmacy coupons https://megaindiapharm.com/# MegaIndiaPharm
xxl mexican pharm: xxl mexican pharm – mexico drug stores pharmacies
pharmacy no prescription required https://discountdrugmart.pro/# discount drug mart pharmacy
Mega India Pharm: Mega India Pharm – mail order pharmacy india
canadian prescription pharmacy https://xxlmexicanpharm.com/# mexican pharmaceuticals online
canadian pharmacy meds reviews: easy canadian pharm – easy canadian pharm
canada pharmacy coupon http://familypharmacy.company/# canadian online pharmacy no prescription
best canadian pharmacy no prescription https://xxlmexicanpharm.com/# xxl mexican pharm
family pharmacy [url=https://familypharmacy.company/#]cheapest pharmacy for prescription drugs[/url] online pharmacy delivery usa
overseas pharmacy no prescription http://xxlmexicanpharm.com/# xxl mexican pharm
pharmacy coupons http://xxlmexicanpharm.com/# mexican pharmaceuticals online
xxl mexican pharm: mexico pharmacies prescription drugs – mexican mail order pharmacies
Online pharmacy USA: Online pharmacy USA – Cheapest online pharmacy
family pharmacy [url=https://familypharmacy.company/#]family pharmacy[/url] online canadian pharmacy coupon
prescription drugs from canada https://megaindiapharm.shop/# MegaIndiaPharm
canada online pharmacy no prescription https://easycanadianpharm.shop/# easy canadian pharm
mexican mail order pharmacies: п»їbest mexican online pharmacies – mexico pharmacies prescription drugs
drug mart: discount drug pharmacy – discount drug mart pharmacy
prescription drugs online https://easycanadianpharm.com/# easy canadian pharm
no prescription pharmacy paypal http://discountdrugmart.pro/# discount drug pharmacy
xxl mexican pharm: xxl mexican pharm – mexican drugstore online
no prescription needed canadian pharmacy http://discountdrugmart.pro/# drug mart
easy canadian pharm: canadian pharmacy reviews – canada pharmacy world
buying prescription drugs from canada http://familypharmacy.company/# Cheapest online pharmacy
international pharmacy no prescription https://discountdrugmart.pro/# drug mart
xxl mexican pharm: xxl mexican pharm – mexican pharmaceuticals online
canadian pharmacy no prescription https://megaindiapharm.com/# Mega India Pharm
canadian pharmacy world coupon https://familypharmacy.company/# Online pharmacy USA
Heya i’m for the first time here. I found this board and I find It really useful &it helped me out much. I hope to give something back and help others like you aided me.Review my blog post; Pure Optimum Keto Burn
xxl mexican pharm [url=https://xxlmexicanpharm.shop/#]best online pharmacies in mexico[/url] xxl mexican pharm
easy canadian pharm: easy canadian pharm – easy canadian pharm
us pharmacy no prescription https://discountdrugmart.pro/# canadian pharmacy without prescription
online pharmacy delivery usa: Cheapest online pharmacy – family pharmacy
I am perpetually thought about this, appreciate itfor posting.Feel free to surf to my blog … Viag Rx
reputable online pharmacy no prescription https://familypharmacy.company/# family pharmacy
easy canadian pharm: easy canadian pharm – canadadrugpharmacy com
buying prescription drugs in mexico: xxl mexican pharm – mexican drugstore online
discount drugs [url=http://discountdrugmart.pro/#]discount drugs[/url] drugmart
Cheapest online pharmacy: family pharmacy – Online pharmacy USA
online pharmacy delivery usa: online pharmacy delivery usa – Online pharmacy USA
best online pharmacy no prescription https://familypharmacy.company/# family pharmacy
canadian pharmacy coupon code https://megaindiapharm.shop/# cheapest online pharmacy india
rxpharmacycoupons https://megaindiapharm.com/# Mega India Pharm
xxl mexican pharm: xxl mexican pharm – buying prescription drugs in mexico online
overseas pharmacy no prescription https://xxlmexicanpharm.com/# mexican border pharmacies shipping to usa
You only have yourself to blame for not asking for a lot more from the get-go.
canadian neighbor pharmacy [url=http://easycanadianpharm.com/#]easy canadian pharm[/url] easy canadian pharm
international pharmacy no prescription https://discountdrugmart.pro/# discount drug mart pharmacy
easy canadian pharm: onlinepharmaciescanada com – easy canadian pharm
MegaIndiaPharm: MegaIndiaPharm – pharmacy website india
no prescription required pharmacy https://familypharmacy.company/# family pharmacy
Best online pharmacy: Online pharmacy USA – Cheapest online pharmacy
online pharmacy discount code https://xxlmexicanpharm.shop/# purple pharmacy mexico price list
discount drug mart pharmacy: drugmart – canadian pharmacy world coupon
online canadian pharmacy review [url=https://easycanadianpharm.com/#]easy canadian pharm[/url] canadian pharmacy sarasota
canada pharmacy coupon http://discountdrugmart.pro/# drugmart
xxl mexican pharm: xxl mexican pharm – xxl mexican pharm
Cheapest online pharmacy: family pharmacy – family pharmacy
non prescription medicine pharmacy https://familypharmacy.company/# online pharmacy delivery usa
drug mart: discount drug mart pharmacy – online pharmacy no prescription needed
discount drug mart pharmacy [url=https://discountdrugmart.pro/#]discount drug mart pharmacy[/url] canadian pharmacy no prescription
rx pharmacy coupons https://xxlmexicanpharm.shop/# mexican pharmaceuticals online
online pharmacy no prescription https://discountdrugmart.pro/# drugmart
Mega India Pharm: Mega India Pharm – MegaIndiaPharm
cheapest pharmacy to fill prescriptions without insurance http://discountdrugmart.pro/# canadian pharmacy without prescription
canadian pharmacy world coupon code https://familypharmacy.company/# family pharmacy
Cheapest online pharmacy [url=https://familypharmacy.company/#]cheapest pharmacy for prescriptions without insurance[/url] online pharmacy delivery usa
easy canadian pharm: easy canadian pharm – easy canadian pharm
lisinopril ibuprofen does lisinopril cause dry mouth
rx pharmacy no prescription https://discountdrugmart.pro/# discount drugs
canadian pharmacy no prescription https://megaindiapharm.com/# indian pharmacy paypal
Online pharmacy USA: Online pharmacy USA – family pharmacy
canadian pharmacy coupon code http://familypharmacy.company/# Online pharmacy USA
canadian pharmacy no prescription needed http://discountdrugmart.pro/# canadian pharmacy no prescription needed
discount drugs: drugmart – drug mart
best no prescription pharmacy https://easycanadianpharm.com/# canada drug pharmacy
canada pharmacy not requiring prescription https://xxlmexicanpharm.com/# xxl mexican pharm
reputable canadian online pharmacy: easy canadian pharm – easy canadian pharm
https://garuda888.top/# Mesin slot dapat dimainkan dalam berbagai bahasa
Banyak pemain menikmati jackpot harian di slot http://preman69.tech/# Slot dengan pembayaran tinggi selalu diminati
bonaslot [url=http://bonaslot.site/#]BonaSlot[/url] Banyak kasino memiliki program loyalitas untuk pemain
Slot menawarkan kesenangan yang mudah diakses https://preman69.tech/# Kasino selalu memperbarui mesin slotnya
Mesin slot sering diperbarui dengan game baru: slot88 – slot 88
http://bonaslot.site/# Kasino sering memberikan hadiah untuk pemain setia
Mesin slot menawarkan pengalaman bermain yang cepat http://garuda888.top/# Kasino menyediakan layanan pelanggan yang baik
Kasino selalu memperbarui mesin slotnya http://garuda888.top/# Permainan slot bisa dimainkan dengan berbagai taruhan
Kasino mendukung permainan bertanggung jawab: BonaSlot – bonaslot
https://slot88.company/# Jackpot besar bisa mengubah hidup seseorang
slot 88 [url=https://slot88.company/#]slot88.company[/url] Slot memberikan kesempatan untuk menang besar
Pemain sering berbagi tips untuk menang: slotdemo – slot demo gratis
Beberapa kasino memiliki area khusus untuk slot http://slot88.company/# Slot modern memiliki grafik yang mengesankan
п»їKasino di Indonesia sangat populer di kalangan wisatawan: akun demo slot – slotdemo
http://slotdemo.auction/# Permainan slot bisa dimainkan dengan berbagai taruhan
preman69 slot [url=http://preman69.tech/#]preman69[/url] Slot menawarkan kesenangan yang mudah diakses
Beberapa kasino memiliki area khusus untuk slot https://slot88.company/# Banyak pemain berusaha untuk mendapatkan jackpot
Mesin slot menawarkan berbagai tema menarik: slot 88 – slot 88
https://slot88.company/# п»їKasino di Indonesia sangat populer di kalangan wisatawan
Pemain harus menetapkan batas saat bermain http://slotdemo.auction/# Kasino di Indonesia menyediakan hiburan yang beragam
Keseruan bermain slot selalu menggoda para pemain http://bonaslot.site/# Pemain sering berbagi tips untuk menang
Beberapa kasino memiliki area khusus untuk slot: bonaslot – bonaslot
Mesin slot baru selalu menarik minat https://bonaslot.site/# Kasino selalu memperbarui mesin slotnya
http://garuda888.top/# Banyak kasino memiliki program loyalitas untuk pemain
http://preman69.tech/# Pemain bisa menikmati slot dari kenyamanan rumah
Thẳng Bóng Đá Thời Điểm Hôm Naycúp bóng đá nữ toàn cầuNếu cứ đùa như cách vừa tiêu diệt Everton cho tới 3-1 bên trên sảnh khách
Slot dengan tema film terkenal menarik banyak perhatian http://garuda888.top/# Banyak pemain mencari mesin dengan RTP tinggi
visit my site https://rocket-pool.us/
Kasino di Indonesia menyediakan hiburan yang beragam: slot88 – slot88.company
garuda888 [url=http://garuda888.top/#]garuda888.top[/url] Mesin slot baru selalu menarik minat
Slot menawarkan berbagai jenis permainan bonus https://preman69.tech/# Kasino di Jakarta memiliki berbagai pilihan permainan
Mesin slot digital semakin banyak diminati https://bonaslot.site/# Kasino di Jakarta memiliki berbagai pilihan permainan
Kasino menawarkan pengalaman bermain yang seru: akun demo slot – slot demo
http://preman69.tech/# Slot menjadi bagian penting dari industri kasino
Kasino memastikan keamanan para pemain dengan baik https://slot88.company/# Pemain bisa menikmati slot dari kenyamanan rumah
garuda888.top [url=https://garuda888.top/#]garuda888 slot[/url] Mesin slot dapat dimainkan dalam berbagai bahasa
https://preman69.tech/# Slot dengan bonus putaran gratis sangat populer
Mesin slot sering diperbarui dengan game baru https://slotdemo.auction/# Banyak kasino menawarkan permainan langsung yang seru
Kasino memiliki suasana yang energik dan menyenangkan https://slotdemo.auction/# Banyak pemain menikmati bermain slot secara online
bonaslot.site [url=http://bonaslot.site/#]BonaSlot[/url] Mesin slot sering diperbarui dengan game baru
https://garuda888.top/# Pemain sering berbagi tips untuk menang
Jackpot progresif menarik banyak pemain: garuda888.top – garuda888 slot
Banyak pemain berusaha untuk mendapatkan jackpot http://slot88.company/# Kasino di Bali menarik banyak pengunjung
https://slotdemo.auction/# Kasino menawarkan pengalaman bermain yang seru
nice article, have a look at my
Permainan slot bisa dimainkan dengan berbagai taruhan: slot 88 – slot 88
BonaSlot [url=https://bonaslot.site/#]BonaSlot[/url] Beberapa kasino memiliki area khusus untuk slot
Banyak pemain menikmati jackpot harian di slot http://preman69.tech/# Pemain bisa menikmati slot dari kenyamanan rumah
These are really impressive ideas in about blogging.You have touched some nice things here. Any way keep up wrinting.
nice article ave a look at my site “https://www.newsbreak.com/crypto-space-hub-313321940/3799652652916-top-crypto-investments-in-2025-bitcoin-ai-projects-tokenized-assets”
https://garuda888.top/# Kasino memiliki suasana yang energik dan menyenangkan
Mesin slot dapat dimainkan dalam berbagai bahasa https://preman69.tech/# Slot klasik tetap menjadi favorit banyak orang
https://garuda888.top/# Slot menawarkan kesenangan yang mudah diakses
https://spookyswap-r-2.gitbook.io/en-us/
Permainan slot mudah dipahami dan menyenangkan https://bonaslot.site/# Mesin slot menawarkan berbagai tema menarik
bonaslot [url=https://bonaslot.site/#]bonaslot[/url] Pemain bisa menikmati slot dari kenyamanan rumah
Slot dengan tema budaya lokal menarik perhatian: slot88 – slot 88
Slot dengan tema budaya lokal menarik perhatian http://bonaslot.site/# Mesin slot digital semakin banyak diminati
https://bonaslot.site/# Slot menjadi bagian penting dari industri kasino
Kasino di Jakarta memiliki berbagai pilihan permainan https://preman69.tech/# Slot dengan tema budaya lokal menarik perhatian
Mesin slot menawarkan berbagai tema menarik: preman69.tech – preman69 slot
Pemain sering berbagi tips untuk menang http://preman69.tech/# Slot dengan tema film terkenal menarik banyak perhatian
garuda888 slot [url=https://garuda888.top/#]garuda888 slot[/url] Slot dengan grafis 3D sangat mengesankan
Beberapa kasino memiliki area khusus untuk slot https://bonaslot.site/# Slot menjadi bagian penting dari industri kasino
https://preman69.tech/# Kasino di Jakarta memiliki berbagai pilihan permainan
https://casino-fiable.info
Slot dengan grafis 3D sangat mengesankan: slot88.company – slot88.company
Permainan slot mudah dipahami dan menyenangkan http://bonaslot.site/# Banyak pemain menikmati jackpot harian di slot
https://preman69.tech/# Kasino menawarkan pengalaman bermain yang seru
amoxicillin capsules 250mg: where to buy amoxicillin over the counter – amoxicillin price canada
where to buy generic clomid no prescription [url=http://clmhealthpharm.com/#]ClmHealthPharm[/url] can i get clomid online
where can i get doxycycline uk: doxycycline 50mg tablets price – doxycycline cap tab 100mg
amoxicillin generic brand: amoxicillin 1000 mg capsule – how much is amoxicillin
Managing money is easier with Woofi Finance!
amoxicillin 500 mg without prescription: AmoHealthPharm – generic amoxicillin online
Visit spookyswap and click “Connect Wallet.”
https://zithropharm.com/# zithromax 250 price
where to buy cheap clomid without dr prescription: buy generic clomid prices – where to buy generic clomid without prescription
amoxicillin 500 mg purchase without prescription [url=https://amohealthpharm.shop/#]generic amoxicillin cost[/url] generic amoxicillin 500mg
where to buy clomid without dr prescription: ClmHealthPharm – can you buy cheap clomid without dr prescription
https://spookyswap-tm-1.gitbook.io/en-us/
https://clmhealthpharm.com/# cost of generic clomid pills
zithromax 250 price: zithromax 500 mg – how much is zithromax 250 mg
order amoxicillin online uk: Amo Health Pharm – amoxicillin 875 mg tablet
http://zithropharm.com/# order zithromax without prescription
get cheap clomid without a prescription [url=https://clmhealthpharm.com/#]can i order generic clomid pill[/url] cost of clomid pill
doxycycline tablets cost: doxycycline 100 mg capsule price – doxycycline 40 mg capsule
can i buy generic clomid online: ClmHealthPharm – where can i get clomid pill
buy doxycycline united states: Dox Health Pharm – cost of doxycycline 50 mg
https://amohealthpharm.com/# antibiotic amoxicillin
https://spookyswap-2.gitbook.io/en-us
Trust is earned, and spooky swap has definitely earned mine.
https://r-guide-spookyswap-r.gitbook.io/en-us
order doxycycline online uk: Dox Health Pharm – doxycycline 60 mg
zithromax 500 without prescription [url=http://zithropharm.com/#]can you buy zithromax over the counter[/url] zithromax 500 mg lowest price online
http://amohealthpharm.com/# amoxicillin 500 mg brand name
cheapest doxycycline uk: Dox Health Pharm – doxycycline 75 mg
zithromax for sale online: Zithro Pharm – can you buy zithromax over the counter in canada
get cheap clomid online: can i order cheap clomid for sale – buying generic clomid tablets
http://zithropharm.com/# zithromax canadian pharmacy
doxycycline 200 mg [url=https://doxhealthpharm.shop/#]doxycycline 100 mg pill[/url] doxycycline cream over the counter
doxycycline online canada without prescription: DoxHealthPharm – where to buy doxycycline 100mg
http://clmhealthpharm.com/# order cheap clomid pills
doxycycline canada brand name: purchase doxycycline without prescription – doxycycline canada brand name
best crypto site in 2025
amoxicillin brand name: AmoHealthPharm – generic for amoxicillin
https://zithropharm.shop/# zithromax z-pak
zithromax cost canada [url=https://zithropharm.shop/#]Zithro Pharm[/url] zithromax 250 mg pill
amoxicillin pharmacy price: AmoHealthPharm – amoxicillin 500 mg brand name
doxycycline 100 cost: Dox Health Pharm – doxycycline 100mg capsules cost
can i order generic clomid price: can i order generic clomid now – clomid tablet
where to get generic clomid pill: how can i get cheap clomid without prescription – can you get clomid online
http://amohealthpharm.com/# where can i buy amoxicillin over the counter uk
where can i buy amoxicillin over the counter [url=http://amohealthpharm.com/#]AmoHealthPharm[/url] amoxicillin 800 mg price
amoxicillin 500mg capsule cost: Amo Health Pharm – prescription for amoxicillin
WOOFi Finance: A Comprehensive Guide to One of the Leading DeFi Platforms in 2025, https://sites.google.com/view/woofi–finance/
buy cheap generic zithromax: ZithroPharm – buy zithromax 1000 mg online
WOOFi Finance Trading Guide: How to Trade Crypto in 2025
vente de mГ©dicament en ligne https://tadalafilmeilleurprix.com/# Achat mГ©dicament en ligne fiable
Achat mГ©dicament en ligne fiable: kamagra pas cher – pharmacie en ligne avec ordonnance
pharmacie en ligne france livraison internationale: acheter kamagra site fiable – Pharmacie sans ordonnance
pharmacie en ligne avec ordonnance http://pharmaciemeilleurprix.com/# pharmacies en ligne certifiГ©es
Achat mГ©dicament en ligne fiable: kamagra en ligne – pharmacie en ligne sans ordonnance
https://tadalafilmeilleurprix.com/# Pharmacie en ligne livraison Europe
pharmacie en ligne avec ordonnance
acheter mГ©dicament en ligne sans ordonnance: pharmacie en ligne sans ordonnance – Pharmacie en ligne livraison Europe
trouver un mГ©dicament en pharmacie: pharmacie en ligne pas cher – trouver un mГ©dicament en pharmacie
pharmacie en ligne fiable: Achat mГ©dicament en ligne fiable – pharmacie en ligne france livraison belgique
https://viagrameilleurprix.shop/# Viagra vente libre pays
trouver un mГ©dicament en pharmacie
pharmacie en ligne france livraison internationale [url=http://pharmaciemeilleurprix.com/#]pharmacie en ligne[/url] pharmacie en ligne
pharmacie en ligne france fiable http://kamagrameilleurprix.com/# acheter mГ©dicament en ligne sans ordonnance
how to get cytotec online – cytotec pill canada where can i get cytotec over the counter
trouver un mГ©dicament en pharmacie: pharmacie en ligne france fiable – trouver un mГ©dicament en pharmacie
pharmacie en ligne france livraison belgique: cialis sans ordonnance – Pharmacie sans ordonnance
pharmacie en ligne avec ordonnance https://kamagrameilleurprix.com/# acheter mГ©dicament en ligne sans ordonnance
pharmacie en ligne [url=https://tadalafilmeilleurprix.shop/#]Cialis sans ordonnance 24h[/url] pharmacie en ligne sans ordonnance
pharmacie en ligne livraison europe http://tadalafilmeilleurprix.com/# pharmacie en ligne
pharmacie en ligne pas cher: cialis generique – pharmacie en ligne france livraison internationale
pharmacie en ligne france livraison belgique: cialis prix – pharmacie en ligne france livraison internationale
pharmacie en ligne france livraison internationale: Acheter Cialis – acheter mГ©dicament en ligne sans ordonnance
I cannot thank you enough for the article post.Thanks Again. Great.
pharmacie en ligne fiable [url=https://pharmaciemeilleurprix.com/#]Pharmacies en ligne certifiees[/url] Achat mГ©dicament en ligne fiable
Really informative article. Will read on…
https://viagrameilleurprix.com/# Viagra homme prix en pharmacie
pharmacie en ligne pas cher
Viagra sans ordonnance 24h suisse: Viagra sans ordonnance 24h – Viagra sans ordonnance livraison 48h
pharmacie en ligne pas cher: Tadalafil sans ordonnance en ligne – pharmacie en ligne france fiable
http://kamagrameilleurprix.com/# trouver un mГ©dicament en pharmacie
pharmacie en ligne france livraison internationale
Pharmacie en ligne livraison Europe http://kamagrameilleurprix.com/# acheter mГ©dicament en ligne sans ordonnance
п»їpharmacie en ligne france [url=https://tadalafilmeilleurprix.com/#]cialis generique[/url] Pharmacie sans ordonnance
Achat mГ©dicament en ligne fiable: cialis generique – vente de mГ©dicament en ligne
Viagra gГ©nГ©rique sans ordonnance en pharmacie: acheter du viagra – Prix du Viagra en pharmacie en France
https://kamagrameilleurprix.com/# acheter mГ©dicament en ligne sans ordonnance
trouver un mГ©dicament en pharmacie
acheter mГ©dicament en ligne sans ordonnance https://pharmaciemeilleurprix.shop/# pharmacie en ligne fiable
acheter mГ©dicament en ligne sans ordonnance: Cialis sans ordonnance 24h – п»їpharmacie en ligne france
pharmacie en ligne livraison europe [url=http://kamagrameilleurprix.com/#]kamagra en ligne[/url] vente de mГ©dicament en ligne
pharmacie en ligne france pas cher https://kamagrameilleurprix.com/# pharmacie en ligne fiable
https://viagrameilleurprix.com/# Viagra sans ordonnance livraison 24h
pharmacie en ligne fiable
pharmacie en ligne fiable: Pharmacie Internationale en ligne – pharmacie en ligne livraison europe
https://kamagrameilleurprix.shop/# pharmacie en ligne france livraison belgique
pharmacie en ligne
Viagra pas cher paris: viagra en ligne – Viagra femme sans ordonnance 24h
pharmacie en ligne france livraison belgique: Acheter Cialis – pharmacie en ligne sans ordonnance
pharmacie en ligne france livraison internationale [url=https://kamagrameilleurprix.com/#]kamagra en ligne[/url] trouver un mГ©dicament en pharmacie
Le gГ©nГ©rique de Viagra: viagra en ligne – Viagra vente libre allemagne
pharmacies en ligne certifiГ©es https://pharmaciemeilleurprix.shop/# pharmacies en ligne certifiГ©es
https://tadalafilmeilleurprix.shop/# pharmacie en ligne livraison europe
pharmacie en ligne avec ordonnance
pharmacie en ligne sans ordonnance: kamagra livraison 24h – pharmacie en ligne sans ordonnance
pharmacie en ligne france pas cher http://kamagrameilleurprix.com/# п»їpharmacie en ligne france
https://viagrameilleurprix.com/# Acheter viagra en ligne livraison 24h
Pharmacie sans ordonnance
Viagra sans ordonnance 24h Amazon: Viagra sans ordonnance 24h – Viagra Pfizer sans ordonnance
pharmacie en ligne sans ordonnance [url=http://tadalafilmeilleurprix.com/#]cialis sans ordonnance[/url] pharmacie en ligne pas cher
Pharmacie sans ordonnance: kamagra en ligne – п»їpharmacie en ligne france
Very neat blog post.Really thank you! Great.
pharmacie en ligne france livraison belgique: acheter kamagra site fiable – pharmacie en ligne pas cher
Great, thanks for sharing this article.Really looking forward to read more. Keep writing.
http://tadalafilmeilleurprix.com/# acheter mГ©dicament en ligne sans ordonnance
pharmacie en ligne france livraison belgique
What’s up, yes this article is really fastidious and I have learned lotof things from it on the topic of blogging. thanks.
I think this is a real great blog article.Thanks Again. Want more.
Acheter Sildenafil 100mg sans ordonnance: viagra sans ordonnance – Viagra homme prix en pharmacie
acheter mГ©dicament en ligne sans ordonnance https://viagrameilleurprix.shop/# п»їViagra sans ordonnance 24h
Viagra homme sans ordonnance belgique: Acheter Viagra Cialis sans ordonnance – Viagra sans ordonnance 24h Amazon
vente de mГ©dicament en ligne https://viagrameilleurprix.shop/# Viagra homme prix en pharmacie sans ordonnance
pharmacie en ligne: kamagra gel – Pharmacie sans ordonnance
https://pharmaciemeilleurprix.shop/# pharmacie en ligne avec ordonnance
pharmacie en ligne pas cher
Pharmacie en ligne livraison Europe: pharmacie en ligne sans ordonnance – pharmacie en ligne livraison europe
Hey, thanks for the article.Really thank you! Fantastic.
pharmacie en ligne france livraison internationale [url=https://kamagrameilleurprix.shop/#]kamagra oral jelly[/url] vente de mГ©dicament en ligne
pharmacie en ligne avec ordonnance https://tadalafilmeilleurprix.shop/# pharmacie en ligne france livraison belgique
Viagra vente libre allemagne: Viagra pharmacie – Viagra sans ordonnance livraison 24h
https://kamagrameilleurprix.com/# pharmacie en ligne
п»їpharmacie en ligne france
Viagra homme prix en pharmacie sans ordonnance: acheter du viagra – Viagra pas cher livraison rapide france
Pharmacie en ligne livraison Europe https://kamagrameilleurprix.shop/# pharmacies en ligne certifiГ©es
pharmacie en ligne pas cher: kamagra en ligne – acheter mГ©dicament en ligne sans ordonnance
pharmacie en ligne fiable [url=https://kamagrameilleurprix.shop/#]kamagra en ligne[/url] Pharmacie sans ordonnance
https://kamagrameilleurprix.com/# pharmacie en ligne france pas cher
Achat mГ©dicament en ligne fiable
pharmacie en ligne france pas cher: achat kamagra – vente de mГ©dicament en ligne
pharmacie en ligne france livraison belgique: kamagra oral jelly – pharmacie en ligne france livraison internationale
pharmacie en ligne fiable: pharmacie en ligne france pas cher – п»їpharmacie en ligne france
pharmacie en ligne https://tadalafilmeilleurprix.com/# pharmacie en ligne france fiable
SildГ©nafil Teva 100 mg acheter: viagra sans ordonnance – Viagra pas cher paris
https://tadalafilmeilleurprix.com/# п»їpharmacie en ligne france
Pharmacie en ligne livraison Europe
п»їpharmacie en ligne france http://kamagrameilleurprix.com/# pharmacie en ligne france livraison internationale
pharmacie en ligne avec ordonnance: п»їpharmacie en ligne france – acheter mГ©dicament en ligne sans ordonnance
three months, or a year, and the there is the God of War.
п»їpharmacie en ligne france https://tadalafilmeilleurprix.shop/# pharmacie en ligne sans ordonnance
https://tadalafilmeilleurprix.com/# п»їpharmacie en ligne france
pharmacie en ligne
п»їpharmacie en ligne france [url=https://kamagrameilleurprix.com/#]achat kamagra[/url] pharmacie en ligne sans ordonnance
pharmacie en ligne france fiable: achat kamagra – vente de mГ©dicament en ligne
pharmacie en ligne pas cher https://tadalafilmeilleurprix.shop/# Achat mГ©dicament en ligne fiable
https://viagrameilleurprix.shop/# Viagra 100 mg sans ordonnance
pharmacie en ligne france livraison internationale
acheter mГ©dicament en ligne sans ordonnance: Tadalafil sans ordonnance en ligne – acheter mГ©dicament en ligne sans ordonnance
pharmacie en ligne livraison europe https://viagrameilleurprix.com/# Viagra homme prix en pharmacie sans ordonnance
п»їpharmacie en ligne france: Cialis sans ordonnance 24h – trouver un mГ©dicament en pharmacie
Pharmacie Internationale en ligne [url=https://pharmaciemeilleurprix.com/#]п»їpharmacie en ligne france[/url] pharmacie en ligne sans ordonnance
Viagra gГ©nГ©rique sans ordonnance en pharmacie: viagra en ligne – Viagra vente libre pays
acheter mГ©dicament en ligne sans ordonnance: kamagra gel – pharmacie en ligne france livraison belgique
https://tadalafilmeilleurprix.shop/# pharmacie en ligne pas cher
pharmacies en ligne certifiГ©es
Pharmacie Internationale en ligne [url=https://kamagrameilleurprix.shop/#]kamagra pas cher[/url] pharmacie en ligne fiable
pharmacie en ligne pas cher http://kamagrameilleurprix.com/# pharmacies en ligne certifiГ©es
Viagra pas cher livraison rapide france: Acheter Viagra Cialis sans ordonnance – Viagra vente libre pays
Stargate Bridge is the best way to move assets across blockchains in 2025. Instant transfers and low fees make it a must-have for DeFi traders!
Move assets seamlessly between blockchains with Stargate Bridge. Fast, secure, and cost-effective!
http://pharmaciemeilleurprix.com/# Pharmacie sans ordonnance
Pharmacie Internationale en ligne
pharmacie en ligne france livraison belgique http://tadalafilmeilleurprix.com/# pharmacie en ligne fiable
Very neat blog post.Thanks Again. Much obliged.
Viagra pas cher livraison rapide france: Viagra sans ordonnance 24h – Viagra homme sans ordonnance belgique
trouver un mГ©dicament en pharmacie [url=http://kamagrameilleurprix.com/#]kamagra livraison 24h[/url] pharmacie en ligne livraison europe
http://tadalafilmeilleurprix.com/# Pharmacie sans ordonnance
Pharmacie sans ordonnance
acheter mГ©dicament en ligne sans ordonnance http://viagrameilleurprix.com/# SildГ©nafil 100 mg prix en pharmacie en France
pharmacies en ligne certifiГ©es: pharmacie en ligne – pharmacie en ligne
pharmacie en ligne france fiable https://pharmaciemeilleurprix.shop/# Achat mГ©dicament en ligne fiable
http://viagrameilleurprix.com/# Viagra homme sans ordonnance belgique
Pharmacie Internationale en ligne
Viagra pas cher livraison rapide france: viagra en ligne – Viagra vente libre pays
pharmacie en ligne avec ordonnance [url=https://pharmaciemeilleurprix.com/#]pharmacie en ligne pas cher[/url] vente de mГ©dicament en ligne
Pharmacie en ligne livraison Europe https://tadalafilmeilleurprix.shop/# acheter mГ©dicament en ligne sans ordonnance
https://tadalafilmeilleurprix.com/# acheter mГ©dicament en ligne sans ordonnance
Pharmacie en ligne livraison Europe
Achat mГ©dicament en ligne fiable https://tadalafilmeilleurprix.com/# pharmacie en ligne pas cher
http://kamagrameilleurprix.com/# pharmacies en ligne certifiГ©es
п»їpharmacie en ligne france
pharmacie en ligne sans ordonnance: Cialis sans ordonnance 24h – pharmacie en ligne france livraison belgique
Pharmacie en ligne livraison Europe https://kamagrameilleurprix.com/# trouver un mГ©dicament en pharmacie
http://kamagrameilleurprix.com/# Achat mГ©dicament en ligne fiable
Pharmacie en ligne livraison Europe
Looking forward to reading more. Great article post.Much thanks again. Really Cool.
pharmacie en ligne france fiable https://pharmaciemeilleurprix.shop/# pharmacie en ligne
pharmacie en ligne france pas cher [url=https://kamagrameilleurprix.com/#]acheter kamagra site fiable[/url] pharmacie en ligne france livraison belgique
http://plinkodeutsch.com/# plinko germany
plinko geld verdienen: plinko ball – plinko casino
A round of applause for your article post.Really looking forward to read more. Fantastic.
PlinkoFr: plinko fr – PlinkoFr
https://plinkocasi.com/# Plinko casino game
https://plinkocasinonl.com/# plinko nl
I’ve personally used Stargate Bridge for transactions, and I can say it’s one of the most reliable bridges in the crypto space!
plinko ball: plinko – avis plinko
plinko ball [url=https://plinkodeutsch.com/#]PlinkoDeutsch[/url] Plinko Deutsch
Plinko game: Plinko app – Plinko game for real money
https://plinkocasinonl.com/# plinko nederland
plinko: plinko betrouwbaar – plinko nederland
pinco.legal: pinco – pinco slot
plinko germany: plinko ball – plinko geld verdienen
Thanks so much for the article post.Thanks Again. Will read on…
plinko spelen: plinko – plinko betrouwbaar
plinko germany: plinko – PlinkoDeutsch
Great article post.Much thanks again. Great.
https://plinkofr.com/# plinko france
Plinko online game: Plinko casino game – Plinko games
plinko france: plinko – plinko france
https://plinkocasi.com/# Plinko game
http://pinco.legal/# pinco slot
plinko ball: Plinko Deutsch – plinko ball
https://plinkofr.com/# plinko france
http://plinkocasinonl.com/# plinko nl
plinko nl: plinko spelen – plinko nl
pinco casino [url=http://pinco.legal/#]pinco legal[/url] pinco slot
Plinko game for real money: Plinko online – Plinko game for real money
http://plinkodeutsch.com/# plinko erfahrung
http://plinkodeutsch.com/# plinko ball
Plinko casino game: Plinko app – Plinko-game
https://plinkodeutsch.shop/# plinko geld verdienen
plinko erfahrung: plinko wahrscheinlichkeit – plinko ball
plinko casino nederland: plinko nl – plinko spelen
Plinko game for real money [url=https://plinkocasi.com/#]Plinko games[/url] Plinko online game
https://plinkofr.shop/# plinko
plinko spelen: plinko betrouwbaar – plinko casino
plinko game: plinko game – plinko ball
https://plinkocasi.com/# Plinko games
https://plinkofr.shop/# plinko argent reel avis
https://plinkocasinonl.shop/# plinko spelen
Plinko casino game: Plinko app – Plinko online
https://plinkocasinonl.com/# plinko spelen
plinko: plinko casino – plinko betrouwbaar
https://plinkocasinonl.com/# plinko spelen
plinko game [url=https://plinkodeutsch.com/#]plinko casino[/url] plinko erfahrung
http://plinkocasi.com/# Plinko online game
A round of applause for your article.Much thanks again. Cool.
https://plinkocasinonl.shop/# plinko
Appreciate you sharing, great blog post.Thanks Again. Really Great.
Plinko online game: Plinko games – Plinko online game
pinco: pinco legal – pinco casino
plinko fr [url=http://plinkofr.com/#]PlinkoFr[/url] plinko casino
pinco.legal: pinco – pinco.legal
http://plinkodeutsch.com/# plinko game
pinco casino: pinco legal – pinco legal
plinko casino: plinko geld verdienen – plinko erfahrung
Plinko games: Plinko casino game – Plinko game
Plinko-game [url=https://plinkocasi.com/#]Plinko casino game[/url] Plinko game for real money
https://certpharm.com/# mexican online pharmacies prescription drugs
Mexican Cert Pharm: Best Mexican pharmacy online – best online pharmacies in mexico
mexican drugstore online https://certpharm.shop/# Cert Pharm
mexican pharmacy online: Mexican Cert Pharm – Legit online Mexican pharmacy
mexican pharmacy online: mexican pharmacy online – mexican pharmacy online
medicine in mexico pharmacies [url=https://certpharm.shop/#]Legit online Mexican pharmacy[/url] mexican pharmacy online
medication from mexico pharmacy https://certpharm.com/# Mexican Cert Pharm
buying prescription drugs in mexico: mexican pharmacy – Cert Pharm
Best Mexican pharmacy online: Cert Pharm – mexican drugstore online
https://certpharm.com/# Legit online Mexican pharmacy
mexican border pharmacies shipping to usa [url=https://certpharm.shop/#]mexican pharmacy[/url] reputable mexican pharmacies online
mexican pharmaceuticals online https://certpharm.com/# buying prescription drugs in mexico
mexican pharmacy: mexican pharmacy – mexican pharmacy online
mexican mail order pharmacies: Cert Pharm – mexican pharmacy
Mexican Cert Pharm [url=http://certpharm.com/#]mexican pharmacy[/url] Mexican Cert Pharm
https://certpharm.shop/# Mexican Cert Pharm
mexican pharmacy: Cert Pharm – Cert Pharm
mexican border pharmacies shipping to usa https://certpharm.shop/# Best Mexican pharmacy online
https://certpharm.shop/# Mexican Cert Pharm
Major thankies for the blog.Much thanks again. Really Great.
Mexican Cert Pharm [url=http://certpharm.com/#]Mexican Cert Pharm[/url] mexican pharmacy
mexican pharmacy: Mexican Cert Pharm – Cert Pharm
mexico drug stores pharmacies http://certpharm.com/# mexican pharmacy
https://certpharm.com/# buying prescription drugs in mexico
п»їbest mexican online pharmacies: mexican pharmacy – Mexican Cert Pharm
mexican border pharmacies shipping to usa https://certpharm.com/# Legit online Mexican pharmacy
https://certpharm.com/# Mexican Cert Pharm
mexican pharmacy: Legit online Mexican pharmacy – mexican pharmacy
Best Mexican pharmacy online [url=https://certpharm.com/#]Best Mexican pharmacy online[/url] best online pharmacies in mexico
п»їbest mexican online pharmacies http://certpharm.com/# mexican pharmacy
Express Canada Pharm: pharmacy wholesalers canada – Express Canada Pharm
https://expresscanadapharm.shop/# Express Canada Pharm
safe reliable canadian pharmacy: Express Canada Pharm – Express Canada Pharm
https://expresscanadapharm.com/# Express Canada Pharm
Express Canada Pharm: canadian pharmacy ratings – canadian pharmacy 24h com
Express Canada Pharm: drugs from canada – Express Canada Pharm
vipps canadian pharmacy [url=http://expresscanadapharm.com/#]Express Canada Pharm[/url] Express Canada Pharm
best canadian pharmacy to buy from: Express Canada Pharm – Express Canada Pharm
Express Canada Pharm: Express Canada Pharm – best canadian pharmacy
Express Canada Pharm: northwest canadian pharmacy – canadian pharmacy 365
reputable canadian pharmacy: canada ed drugs – Express Canada Pharm
77 canadian pharmacy [url=http://expresscanadapharm.com/#]Express Canada Pharm[/url] Express Canada Pharm
canadian world pharmacy: Express Canada Pharm – Express Canada Pharm
http://expresscanadapharm.com/# canada ed drugs
canada pharmacy online legit [url=https://expresscanadapharm.shop/#]canadian pharmacy no scripts[/url] best canadian pharmacy
Thank you ever so for you article.Much thanks again. Much obliged.
Express Canada Pharm: Express Canada Pharm – Express Canada Pharm
https://expresscanadapharm.com/# Express Canada Pharm
Looking forward to reading more. Great blog post.Thanks Again. Want more.
Long-Term Effects.
where to buy cheap cipro online
The free blood pressure check is a nice touch.
A pharmacy that feels like family.
https://clomidpharm24.top/
Global expertise that’s palpable with every service.
A true gem in the international pharmacy sector.
can i order cytotec pill
Their health and beauty section is fantastic.
World-class service at every touchpoint.
clomid buy
They have a great selection of wellness products.
They bridge the gap between countries with their service.
https://cipropharm24.top/
Their medication synchronization service is fantastic.
I appreciate the range of payment options they offer.
cost clomid without prescription
Their digital prescription service is innovative and efficient.
The one-stop solution for all international medication requirements.
[url=https://lisinoprilpharm24.top/#]can i buy lisinopril without insurance[/url]|[url=https://clomidpharm24.top/#]where to buy clomid tablets[/url]|[url=https://cytotecpharm24.top/#]where can i get cytotec pills[/url]|[url=https://gabapentinpharm24.top/#]gabapentin another name[/url]|[url=https://cipropharm24.top/#]how to get cheap cipro without prescription[/url]
Always professional, whether dealing domestically or internationally.
Their medication synchronization service is fantastic.
https://lisinoprilpharm24.top/
Quick service without compromising on quality.
I love the convenient location of this pharmacy.
can you buy cheap clomid without insurance
Impressed with their wide range of international medications.
A true gem in the international pharmacy sector.
can you get cheap lisinopril without rx
A name synonymous with international pharmaceutical trust.
They offer invaluable advice on health maintenance.
https://clomidpharm24.top/
Read information now.
A reliable pharmacy that connects patients globally.
cheap price for gabapentin 600 mg
Some trends of drugs.
All trends of medicament.
where buy generic cytotec tablets
They provide valuable advice on international drug interactions.
Their international team is incredibly knowledgeable.
can i buy cipro without dr prescription
Trustworthy and reliable, every single visit.
The widest range of international brands under one roof.
can i get cheap cipro pills
Outstanding service, no matter where you’re located.
They provide peace of mind with their secure international deliveries.
where can i buy clomid without a prescription
Every pharmacist here is a true professional.
They set the tone for international pharmaceutical excellence.
https://cipropharm24.top/
Impressed with their dedication to international patient care.
I do not even understand how I ended up here, however I assumed this putup was good. I do not know who you’re but certainly you are going to a well-known blogger if you happen to are not already.Cheers!
Their loyalty points system offers great savings.
order cheap cipro online
The widest range of international brands under one roof.
Get here.
[url=https://lisinoprilpharm24.top/#]buy generic lisinopril pills[/url]|[url=https://clomidpharm24.top/#]can you buy clomid pills[/url]|[url=https://cytotecpharm24.top/#]cytotec side[/url]|[url=https://gabapentinpharm24.top/#]flexeril interaction with gabapentin[/url]|[url=https://cipropharm24.top/#]buy generic cipro without a prescription[/url]
Their pharmacists are top-notch; highly trained and personable.
A reliable pharmacy in times of emergencies.
where to buy cheap lisinopril prices
The gold standard for international pharmaceutical services.
They source globally to provide the best care locally.
https://gabapentinpharm24.top/
The staff exudes professionalism and care.
A beacon of reliability and trust.
what is shelf life of gabapentin
They’re globally connected, ensuring the best patient care.
A trusted voice in global health matters.
https://cytotecpharm24.top/
A name synonymous with international pharmaceutical trust.
A true gem in the international pharmacy sector.
can i buy cheap lisinopril price
A pharmacy that keeps up with the times.
They always have the newest products on the market.
[url=https://lisinoprilpharm24.top/#]order generic lisinopril without dr prescription[/url]|[url=https://clomidpharm24.top/#]buy generic clomid pill[/url]|[url=https://cytotecpharm24.top/#]order generic cytotec tablets[/url]|[url=https://gabapentinpharm24.top/#]gabapentin class of drugs[/url]|[url=https://cipropharm24.top/#]how to buy cheap cipro[/url]
What side effects can this medication cause?
Their global perspective enriches local patient care.
https://cytotecpharm24.top/
A stalwart in international pharmacy services.
Everything information about medication.
lisinopril medication purpose
Offering a global gateway to superior medications.
They bridge the gap between countries with their service.
[url=https://lisinoprilpharm24.top/#]lisinopril 20mg[/url]|[url=https://clomidpharm24.top/#]where buy clomid pills[/url]|[url=https://cytotecpharm24.top/#]can i purchase generic cytotec pills[/url]|[url=https://gabapentinpharm24.top/#]gabapentin postoperative pain[/url]|[url=https://cipropharm24.top/#]can you get generic cipro tablets[/url]
The gold standard for international pharmaceutical services.
Their loyalty program offers great deals.
https://cytotecpharm24.top/
Their compounding services are impeccable.
Their international partnerships enhance patient care.
buying generic cytotec without prescription
They bridge global healthcare gaps seamlessly.
All trends of medicament.
can i order generic cipro prices
This pharmacy has a wonderful community feel.
Their global medical liaisons ensure top-quality care.
[url=https://lisinoprilpharm24.top/#]how to get cheap lisinopril online[/url]|[url=https://clomidpharm24.top/#]can i order clomid without a prescription[/url]|[url=https://cytotecpharm24.top/#]cost cheap cytotec no prescription[/url]|[url=https://gabapentinpharm24.top/#]sudden stop of gabapentin[/url]|[url=https://cipropharm24.top/#]can i get cipro[/url]
I value their commitment to customer health.
A universal solution for all pharmaceutical needs.
can i order generic cytotec
Always greeted with warmth and professionalism.
I always find great deals in their monthly promotions.
where can i buy cipro online
Their prices are unbeatable!
Consistently excellent, year after year.
https://gabapentinpharm24.top/
A harmonious blend of local care and global expertise.
Always a step ahead in international healthcare trends.
order cipro pill
They have a fantastic range of supplements.
The one-stop solution for all international medication requirements.
where to buy clomid price
A name synonymous with international pharmaceutical trust.
Their global outlook is evident in their expansive services.
https://clomidpharm24.top/
A beacon of reliability and trust.
The best in town, without a doubt.
[url=https://lisinoprilpharm24.top/#]buying lisinopril no prescription[/url]|[url=https://clomidpharm24.top/#]can i purchase clomid tablets[/url]|[url=https://cytotecpharm24.top/#]cytotec generic and brand name[/url]|[url=https://gabapentinpharm24.top/#]gabapentin leukocytosis[/url]|[url=https://cipropharm24.top/#]where to buy cipro without dr prescription[/url]
Their 24/7 support line is super helpful.
I love the convenient location of this pharmacy.
how to buy cheap cipro prices
Their global approach ensures unparalleled care.
They’re reshaping international pharmaceutical care.
get generic clomid price
Get here.
Quick service without compromising on quality.
https://lisinoprilpharm24.top/
Their global pharmacists’ network is commendable.
Efficient, reliable, and internationally acclaimed.
how to buy cheap cipro pills
They have an impressive roster of international certifications.
Their health and beauty section is fantastic.
buy cytotec pill
What side effects can this medication cause?
Their staff is so knowledgeable and friendly.
https://cipropharm24.top/
Professional, courteous, and attentive – every time.
Their international team is incredibly knowledgeable.
[url=https://lisinoprilpharm24.top/#]buy lisinopril without prescription[/url]|[url=https://clomidpharm24.top/#]get generic clomid without dr prescription[/url]|[url=https://cytotecpharm24.top/#]where can i buy cheap cytotec without rx[/url]|[url=https://gabapentinpharm24.top/#]side effects of medication gabapentin[/url]|[url=https://cipropharm24.top/#]can i purchase cipro for sale[/url]
Their senior citizen discounts are much appreciated.
Their international partnerships enhance patient care.
gabapentin 400 mg beipackzettel
Their digital prescription service is innovative and efficient.
Their global perspective enriches local patient care.
where to buy generic clomid without insurance
They keep a broad spectrum of rare medications.
Read information now.
lisinopril 40 mg generic
Efficient, effective, and always eager to assist.
Always a seamless experience, whether ordering domestically or internationally.
[url=https://lisinoprilpharm24.top/#]can i buy generic lisinopril pills[/url]|[url=https://clomidpharm24.top/#]where to get generic clomid tablets[/url]|[url=https://cytotecpharm24.top/#]buying cheap cytotec without rx[/url]|[url=https://gabapentinpharm24.top/#]ip 102 yellow capsule gabapentin[/url]|[url=https://cipropharm24.top/#]can i order generic cipro without insurance[/url]
A harmonious blend of local care and global expertise.
A touchstone of international pharmacy standards.
lisinopril price in canada
I always feel valued and heard at this pharmacy.
Their international insights have benefited me greatly.
buy generic cafergot
Their patient care is unparalleled.
Global expertise with a personalized touch.
where to buy cipro pills
A cornerstone of our community.
Their global health initiatives are game-changers.
https://clomidpharm24.top/
Speedy service with a smile!
Commonly Used Drugs Charts.
[url=https://lisinoprilpharm24.top/#]where can i buy cheap lisinopril without a prescription[/url]|[url=https://clomidpharm24.top/#]where can i buy cheap clomid without dr prescription[/url]|[url=https://cytotecpharm24.top/#]can you buy cytotec[/url]|[url=https://gabapentinpharm24.top/#]gabapentin brand name[/url]|[url=https://cipropharm24.top/#]buy cipro without insurance[/url]
Their global pharmacists’ network is commendable.
They have a fantastic range of supplements.
where can i get cheap cipro for sale
Always leaving this place satisfied.
Their worldwide outreach programs are commendable.
how can i get generic cipro without a prescription
Always responsive, regardless of time zones.
Medicament prescribing information.
https://cipropharm24.top/
A stalwart in international pharmacy services.
Cautions.
get cheap cipro without prescription
An excellent choice for all pharmaceutical needs.
Efficient, reliable, and internationally acclaimed.
https://cipropharm24.top/
Efficient, effective, and always eager to assist.
Their digital prescription service is innovative and efficient.
[url=https://lisinoprilpharm24.top/#]cost generic lisinopril pills[/url]|[url=https://clomidpharm24.top/#]can you get generic clomid without insurance[/url]|[url=https://cytotecpharm24.top/#]where to buy generic cytotec prices[/url]|[url=https://gabapentinpharm24.top/#]cheap gabapentin[/url]|[url=https://cipropharm24.top/#]how to buy cheap cipro without prescription[/url]
They bridge global healthcare gaps seamlessly.
Get warning information here.
get cytotec price
Their global reputation precedes them.
Trusted by patients from all corners of the world.
how to buy generic cytotec without dr prescription
A pharmacy that takes pride in community service.
online pharmacy india: Fast From India – indian pharmacy online
Enjoyed every bit of your article.Really thank you! Awesome.
mail order pharmacy india: п»їlegitimate online pharmacies india – Fast From India
Fast From India [url=http://fastfromindia.com/#]india online pharmacy[/url] Fast From India
india pharmacy mail order
Appreciate you sharing, great blog article.Much thanks again. Cool.
https://fastfromindia.shop/# Online medicine home delivery
Online medicine home delivery
https://fastfromindia.shop/# Fast From India
indian pharmacies safe
indian pharmacy online: reputable indian online pharmacy – Fast From India
Online medicine order [url=https://fastfromindia.shop/#]Fast From India[/url] best india pharmacy
best india pharmacy
Online medicine order: top online pharmacy india – Fast From India
https://fastfromindia.com/# Fast From India
п»їlegitimate online pharmacies india
india online pharmacy: Fast From India – indianpharmacy com
Fast From India: Fast From India – Fast From India
Fast From India [url=http://fastfromindia.com/#]best online pharmacy india[/url] Fast From India
best india pharmacy
https://fastfromindia.com/# reputable indian online pharmacy
indian pharmacies safe
buy prescription drugs from india: indian pharmacy online – online shopping pharmacy india
online shopping pharmacy india: indianpharmacy com – indian pharmacies safe
https://fastfromindia.com/# online shopping pharmacy india
mail order pharmacy india
Online medicine order: Fast From India – cheapest online pharmacy india
pharmacie en ligne pas cher: Pharma Internationale – Pharmacie Internationale en ligne
https://pharmainternationale.com/# pharmacie en ligne france pas cher
pharmacie en ligne sans ordonnance
Pharma Internationale: Pharma Internationale – pharmacie en ligne france pas cher
pharmacie en ligne france livraison belgique: Pharma Internationale – Pharma Internationale
Pharma Internationale: Pharma Internationale – pharmacie en ligne pas cher
Pharma Internationale [url=https://pharmainternationale.com/#]vente de mГ©dicament en ligne[/url] Pharma Internationale
pharmacie en ligne france fiable: Pharma Internationale – pharmacies en ligne certifiГ©es
https://pharmainternationale.com/# pharmacie en ligne
pharmacie en ligne fiable
Pharma Internationale: Pharma Internationale – Pharmacie en ligne livraison Europe
pharmacie en ligne fiable: Pharmacie en ligne livraison Europe – Pharma Internationale
Pharmacie Internationale en ligne [url=https://pharmainternationale.com/#]Pharma Internationale[/url] Pharma Internationale
п»їpharmacie en ligne france: trouver un mГ©dicament en pharmacie – pharmacie en ligne livraison europe
pharmacie en ligne fiable: pharmacie en ligne sans ordonnance – pharmacie en ligne sans ordonnance
https://farmaciamedic.shop/# farmacias online baratas
farmacia online envГo gratis
Farmacia Medic: Farmacia Medic – Farmacia Medic
Usually I don’t read post on blogs, but I would like to say thatthis write-up very compelled me to take a lookat and do so! Your writing taste has been surprised me. Thank you, very great post.
farmacia online barata [url=https://farmaciamedic.shop/#]Farmacia Medic[/url] farmacia online envГo gratis
Farmacia Medic: Farmacia Medic – farmacias online baratas
Farmacia Medic: Farmacia Medic – Farmacia Medic
Really enjoyed this blog post. Want more.
Farmacia Medic: farmacia online envГo gratis – Farmacia Medic
https://farmaciamedic.com/# farmacia en casa online descuento
Farmacia Medic
farmacia online barcelona [url=https://farmaciamedic.com/#]farmacia online madrid[/url] farmacia online envГo gratis
farmacia online barata: farmacia online espaГ±a envГo internacional – farmacia online envГo gratis
http://farmaciamedic.com/# farmacia online barata y fiable
п»їfarmacia online espaГ±a
farmacia online madrid: farmacia online barcelona – Farmacia Medic
Beats some term may come about cardiovascular causes as bleeding, the use of patients is incredibly established in refractory cardiac. paper writer Lzrltz zwbgbq
https://farmaciamedic.com/# farmacias online seguras
Farmacia Medic
Farmacia Medic [url=https://farmaciamedic.com/#]Farmacia Medic[/url] п»їfarmacia online espaГ±a
farmacias online seguras en espaГ±a: Farmacia Medic – farmacia online barcelona
A fascinating discussion is worth comment. There’s no doubt that that you ought to publish more on this subject, it might not be a taboo subject but generally people don’t speak about such subjects. To the next! Best wishes!!
Top Max Farma: Farmacia online piГ№ conveniente – top farmacia online
Top Max Farma: comprare farmaci online con ricetta – Top Max Farma
At this time I am going away to do my breakfast, when having my breakfast coming yetagain to read more news.
Top Max Farma [url=https://topmaxfarma.com/#]Top Max Farma[/url] acquisto farmaci con ricetta
https://topmaxfarma.shop/# comprare farmaci online all’estero
acquisto farmaci con ricetta [url=https://topmaxfarma.com/#]migliori farmacie online 2024[/url] Top Max Farma
Top Max Farma: Top Max Farma – Farmacia online piГ№ conveniente
Top Max Farma [url=http://topmaxfarma.com/#]Top Max Farma[/url] Top Max Farma
# Harvard University: A Legacy of Excellence and Innovation
## A Brief History of Harvard University
Founded in 1636, **Harvard University** is the oldest and
one of the most prestigious higher education institutions in the United States.
Located in Cambridge, Massachusetts, Harvard has built a global reputation for academic excellence, groundbreaking
research, and influential alumni. From its humble beginnings as a small college established to
educate clergy, it has evolved into a world-leading university
that shapes the future across various disciplines.
## Harvard’s Impact on Education and Research
Harvard is synonymous with **innovation and intellectual leadership**.
The university boasts:
– **12 degree-granting schools**, including the renowned **Harvard Business School**,
**Harvard Law School**, and **Harvard Medical School**.
– **A faculty of world-class scholars**, many of whom are Nobel laureates, Pulitzer Prize winners, and pioneers
in their fields.
– **Cutting-edge research**, with Harvard leading initiatives
in artificial intelligence, public health, climate change, and more.
Harvard’s contribution to research is immense, with billions
of dollars allocated to scientific discoveries and technological advancements each year.
## Notable Alumni: The Leaders of Today and Tomorrow
Harvard has produced some of the **most influential figures** in history, spanning politics,
business, entertainment, and science. Among them are:
– **Barack Obama & John F. Kennedy** – Former U.S. Presidents
– **Mark Zuckerberg & Bill Gates** – Tech visionaries (though Gates did not graduate)
– **Natalie Portman & Matt Damon** – Hollywood icons
– **Malala Yousafzai** – Nobel Prize-winning activist
The university continues to cultivate future leaders who
shape industries and drive global progress.
## Harvard’s Stunning Campus and Iconic Library
Harvard’s campus is a blend of **historical charm and modern innovation**.
With over **200 buildings**, it features:
– The **Harvard Yard**, home to the iconic **John Harvard Statue** (and the famous “three
lies” legend).
– The **Widener Library**, one of the largest university libraries in the world, housing **over 20
million volumes**.
– State-of-the-art research centers, museums, and performing arts venues.
## Harvard Traditions and Student Life
Harvard offers a **rich student experience**, blending academics
with vibrant traditions, including:
– **Housing system:** Students live in one of 12 residential houses, fostering a strong sense of community.
– **Annual Primal Scream:** A unique tradition where students de-stress by running through Harvard Yard before finals!
– **The Harvard-Yale Game:** A historic football rivalry that unites alumni and students.
With over **450 student organizations**, Harvard students engage in a diverse range of extracurricular activities,
from entrepreneurship to performing arts.
## Harvard’s Global Influence
Beyond academics, Harvard drives change in **global policy,
economics, and technology**. The university’s research impacts
healthcare, sustainability, and artificial intelligence, with partnerships across industries
worldwide. **Harvard’s endowment**, the largest of any university,
allows it to fund scholarships, research, and public initiatives,
ensuring a legacy of impact for generations.
## Conclusion
Harvard University is more than just a school—it’s a **symbol of excellence, innovation, and leadership**.
Its **centuries-old traditions, groundbreaking discoveries,
and transformative education** make it one of the most influential institutions in the world.
Whether through its distinguished alumni, pioneering research, or vibrant student life, Harvard continues to shape the future in profound ways.
Would you like to join the ranks of Harvard’s legendary scholars?
The journey starts with a dream—and an application!
https://www.harvard.edu/
ed treatment pills india rx pharmacy – ed medications online
top farmacia online: Top Max Farma – Top Max Farma
https://topmaxfarma.com/# farmacie online autorizzate elenco
comprare farmaci online all’estero [url=https://topmaxfarma.com/#]Farmacia online miglior prezzo[/url] comprare farmaci online all’estero
mexican drugstore online: mexican pharmacy acp – mexican pharmacy acp
canadian king pharmacy: Canadian Pharmacy AAPD – best online canadian pharmacy
reputable indian pharmacies: IndianPharmacyAbp – Indian pharmacy international shipping
http://indianpharmacyabp.com/# Indian pharmacy online
top 10 pharmacies in india
medication from mexico pharmacy: mexico drug stores pharmacies – mexico pharmacies prescription drugs
http://indianpharmacyabp.com/# IndianPharmacyAbp
mexico pharmacies prescription drugs
mexican pharmacy acp: mexican mail order pharmacies – mexican pharmacy acp
mexican pharmacy acp: mexican pharmacy acp – mexican pharmacy acp
Indian Pharmacy Abp: Best online Indian pharmacy – Best online Indian pharmacy
https://canadianpharmacyaapd.shop/# canadian pharmacy meds review
best online pharmacies in mexico
cheapest online pharmacy india: Online medicine home delivery – Best Indian pharmacy
https://mexicanpharmacyacp.shop/# reputable mexican pharmacies online
п»їbest mexican online pharmacies
canadian 24 hour pharmacy: Canadian Pharmacy AAPD – legal canadian pharmacy online
Best online Indian pharmacy: Indian pharmacy online – Best Indian pharmacy
Indian pharmacy international shipping: online pharmacy india – Indian pharmacy online
http://indianpharmacyabp.com/# Indian Pharmacy Abp
pharmacies in mexico that ship to usa
canadian pharmacy ratings: Canadian Pharmacy AAPD – legitimate canadian pharmacy online
mexican pharmacy acp: mexican pharmaceuticals online – mexican pharmacy acp
Indian pharmacy online [url=https://indianpharmacyabp.shop/#]Indian pharmacy online[/url] indian pharmacy
India pharmacy ship to USA: Online medicine home delivery – Indian pharmacy international shipping
best mail order pharmacy canada: canadian valley pharmacy – canada drugstore pharmacy rx
Обмен USDT на карту без задержек!
“http://it-viking.ch/index.php/Exsrocket.ru_23u”
mexican pharmacy acp: mexican pharmacy acp – mexican pharmacy acp
onlinepharmaciescanada com [url=http://canadianpharmacyaapd.com/#]onlinecanadianpharmacy 24[/url] canadian valley pharmacy
mexican pharmacy acp: best online pharmacies in mexico – pharmacies in mexico that ship to usa
Где безопасно продать USDT с минимальными комиссиями?
“https://botdb.win/wiki/User:ArlethaBeattie”
ed meds online canada: canadian pharmacy online store – best mail order pharmacy canada
They ensure global standards in every pill.
can you get lisinopril pills
A beacon of reliability and trust.
legitimate canadian mail order pharmacy: Canadian Pharmacy AAPD – reputable canadian pharmacy
Indian pharmacy online: Best Indian pharmacy – Online medicine home delivery
Major thanks for the article.Really thank you! Great.
Thanks-a-mundo for the article.Really looking forward to read more. Really Great.
canadian pharmacy world reviews [url=http://canadianpharmacyaapd.com/#]buying drugs from canada[/url] canada drugs
canada pharmacy 24h: Canadian Pharmacy AAPD – online pharmacy canada
A round of applause for your article post.Thanks Again. Really Cool.
canadian drug stores: Canadian Pharmacy AAPD – online canadian pharmacy reviews
Appreciate you sharing, great blog article.Much thanks again. Awesome.
mexican pharmacy acp: mexican pharmacy acp – mexican pharmaceuticals online
India pharmacy ship to USA: top 10 online pharmacy in india – Indian Pharmacy Abp
wow, awesome blog post.Really thank you!
Really enjoyed this blog article.Really looking forward to read more.
the canadian drugstore [url=http://canadianpharmacyaapd.com/#]legit canadian pharmacy[/url] canadian drug prices
mexican pharmacy acp: mexican pharmacy acp – mexican pharmacy acp
Appreciate you sharing, great article.Thanks Again. Cool.
Online medicine home delivery: Indian Pharmacy Abp – Best online Indian pharmacy
Always delivering international quality.
get generic cipro without dr prescription
They always offer alternatives and suggestions.
balloon казино официальный сайт [url=https://akhbutina.kz/#]balloon game[/url] Рграйте СЃ СѓРјРѕРј, РЅРѕ РЅРµ забывайте Рѕ веселье.
https://neokomsomol.kz/# Рграйте РїРѕ СЃРІРѕРёРј правилам РЅР° автомате.
Rocket Pool’s Ethereum staking service reaches $1B in TVL
Рграйте РїРѕ СЃРІРѕРёРј правилам РЅР° автомате.: balloon казино – balloon казино играть
balloon игра на деньги [url=https://balloonigra.kz/#]balloon игра на деньги[/url] Казино — это место для больших выигрышей.
Arbitrum whales transfer $18.5M in tokens following $2.3B unlock
Автомат Ballon — идеальный СЃРїРѕСЃРѕР± расслабиться.: balloon казино играть – balloon казино официальный сайт
Ethereum Foundation confirm $1.25M to Tornado Cash defense
Thanks for sharing, this is a fantastic article.Thanks Again. Keep writing.
That is a very good tip especially to those new to the blogosphere. Brief but very accurate infoÖ Appreciate your sharing this one. A must read article!
Баллон — это автомат для настоящих любителей.: balloon казино официальный сайт – balloon игра
Казино предлагает отличные условия для РёРіСЂС‹.: balloon казино – balloon казино официальный сайт
https://balloonigra.kz/# Казино всегда предлагает выгодные акции.
I loved your blog.Thanks Again. Really Cool.
Ballon — это ваш шанс РЅР° победу.: balloon игра на деньги – balloon игра
balloon казино официальный сайт [url=https://akhbutina.kz/#]balloon game[/url] Рграйте РЅР° деньги Рё получайте удовольствиe.
What is the easiest way to copy my WordPress blogs to a new hosting company? Guenna Pooh Weissmann
Howdy! I’m at work browsing your blog from my new iphone! Just wanted to say I love reading through your blog and look forward to all your posts! Carry on the outstanding work!
п»їРРіСЂРѕРІРѕР№ автомат Ballon дарит СЏСЂРєРёРµ эмоции.: balloon казино официальный сайт – balloon игра
Thank you for sharing your info. I really appreciate your efforts and I will be waiting for your next post thanks once again.
Ballon — это РёРіСЂР° СЃ удивительными графиками.: balloon игра на деньги – balloon казино официальный сайт
doctors prescribing hydroxychloroquine near me plaquenil medication
https://neokomsomol.kz/# Найдите свой lucky slot в казино.
Вывел деньги в течение часа, поддержка быстро
ответила.
play fortuna зеркало
Ргровые автоматы делают вечер незабываемым.: balloon игра – balloon game
Analysts : Bitcoin experiencing ‘shakeout,’ not end of 4-year cycle
Ballon — автомат СЃ захватывающим сюжетом.: balloon game – balloon казино
ethereum casino gambling
I loved your article post.
Trust and reliability on a global scale.
generic gabapentin 100 mg photos
Their worldwide outreach programs are commendable.
Казино — это место для больших выигрышей.: balloon казино – balloon казино демо
Macbook akku schnell leer bubikon[…]The info mentioned in the article are several of the very best out there […]
vitality ed pills best ed treatments – ed therapy
Their global reputation precedes them.
buy generic cytotec without insurance
Consistent excellence across continents.
Phantom takes second spot in Apple’s US App Store utilities category
Thanks so much for the blog article.Thanks Again. Awesome.
Ргровые автоматы — шанс РЅР° крупный выигрыш.: balloon казино играть – balloon игра на деньги
https://neokomsomol.kz/# Выигрывайте большие суммы на автоматах!
Hello colleagues, its wonderful paragraph regarding tutoringand fully defined, keep it up allthe time.
Казино — это место для больших выигрышей.: balloon игра – balloon казино демо
A harmonious blend of local care and global expertise.
get generic clomid tablets
Their digital prescription service is innovative and efficient.
What’s Happening i am new to this, I stumbled upon this I have found It absolutely helpful and it hashelped me out loads. I am hoping to give a contribution & help other customers like its helped me.Great job.
Wow, great article.Really thank you! Really Great.
alo789: alo 789 – alo 789
https://k8viet.gurum/# nha cai k8
Great article.
private jet to hire
alo789: alo789 – alo789 chinh th?c
nha cai k8 [url=http://k8viet.gurum/#]k8vip[/url] k8vip
Fantastic article.Thanks Again. Want more.
I am really thankful to the holder of this web site who has shared this greeat piece of writing at
at this time. https://Menbehealth.Wordpress.com/
Elon Musk’s X eyeing capital raise at $44B valuation: Report
https://alo789.auction/# alo789in
https://k8viet.gurum/# k8vip
link vao k8 [url=https://k8viet.guru/#]link vao k8[/url] k8
alo 789: alo789hk – alo 789 dang nh?p
https://alo789.auction/# alo789hk
https://alo789.auction/# alo789 dang nh?p
Im grateful for the blog.Really looking forward to read more. Will read on…
alo 789: alo789hk – alo789 dang nh?p
https://88betviet.pro/# 88bet slot
alo789hk: alo 789 – alo 789
https://alo789.auction/# alo789hk
alo 789 dang nh?p [url=https://alo789.auction/#]alo789hk[/url] alo789hk
88bet slot: 188bet 88bet – 188bet 88bet
Looking forward to reading more. Great blog post.Thanks Again. Cool.
https://alo789.auction/# alo 789 dang nh?p
Really informative blog post.Really looking forward to read more. Fantastic.
alo 789 dang nh?p [url=http://alo789.auction/#]alo 789 dang nh?p[/url] alo 789
http://88betviet.pro/# 88 bet
alo789 chinh th?c: alo789in – alo789hk
Trump Opens 300x Leverage Trade After Call with Putin – Is This the Trade of the Century?
https://k8viet.guru/# k8vip
Enjoyed every bit of your article.Really looking forward to read more. Cool.
789alo [url=http://alo789.auction/#]789alo[/url] alo 789
https://alo789.auction/# alo789 chinh th?c
https://k8viet.guru/# k8
https://k8viet.guru/# link vao k8
Analysts : Bitcoin experiencing ‘shakeout,’ not end of 4-year cycle
alo 789: alo789in – alo789 chinh th?c
k8 [url=http://k8viet.guru/#]k8[/url] k8vip
Thanks for the good writeup. It in truth was a amusement account it.Look complicated to more delivered agreeable from you!By the way, how can we be in contact?
https://88betviet.pro/# 88bet
https://88betviet.pro/# 88 bet
Arbitrum whales transfer $18.5M in tokens following $2.3B unlock
https://88betviet.pro/# nha cai 88bet
link vao k8: k8 – link vao k8
https://88betviet.pro/# keo nha cai 88bet
k8 bet: k8 th? dam – k8
http://interpharmonline.com/# prescription drugs canada buy online
canada discount pharmacy
http://interpharmonline.com/# safe online pharmacies in canada
buying prescription drugs from india: IndiaMedFast.com – cheapest online pharmacy india
https://indiamedfast.shop/# IndiaMedFast.com
canadian pharmacy tampa
canadianpharmacymeds com: canada pharmacy no prescription – canadianpharmacy com
certified canadian pharmacy: InterPharmOnline – canadadrugpharmacy com
https://indiamedfast.com/# IndiaMedFast.com
canadian pharmacy com
https://mexicanpharminter.shop/# Mexican Pharm Inter
MexicanPharmInter: Mexican Pharm International – reliable mexican pharmacies
canadian world pharmacy: certified canada pharmacy online – canadian pharmacy world
https://mexicanpharminter.shop/# Mexican Pharm International
canadian pharmacy drugs online
https://indiamedfast.com/# buying prescription drugs from india
buying prescription drugs from india [url=https://indiamedfast.shop/#]India Med Fast[/url] lowest prescription prices online india
best rated canadian pharmacy: canada pharmacy no prescription – best rated canadian pharmacy
https://interpharmonline.shop/# best canadian pharmacy
canadian drugstore online
https://mexicanpharminter.com/# mexican pharmacy online
누누티비
global pharmacy canada: highest rated canadian online pharmacy – canadian pharmacy cheap
India Med Fast: IndiaMedFast.com – India Med Fast
Hey, thanks for the blog article.Thanks Again. Fantastic.
เช่ารถกระเช้าในพื้นที่
http://mexicanpharminter.com/# mexican pharmacy online
cross border pharmacy canada
the canadian drugstore: canada pharmacy no prescription – canadian pharmacy checker
http://indiamedfast.com/# order medicines online india
canadian pharmacy 24: canadian drugstore online no prescription – canada drug pharmacy
mexican drug stores online [url=http://mexicanpharminter.com/#]mexican pharmacy online[/url] MexicanPharmInter
http://interpharmonline.com/# canada drugs
canadian drugs
lowest prescription prices online india: lowest prescription prices online india – india pharmacy without prescription
canada pharmacy world: fda approved canadian online pharmacies – pharmacy canadian
https://interpharmonline.com/# canadian online pharmacy
safe canadian pharmacy: legitimate canadian pharmacies online – canada cloud pharmacy
http://tadalafileasybuy.com/# Tadalafil Easy Buy
Officiele Kamagra van Nederland: kamagra gel kopen – kamagra gel kopen
https://kamagrakopen.pro/# kamagra 100mg kopen
kamagra 100mg kopen [url=https://kamagrakopen.pro/#]Kamagra[/url] kamagra pillen kopen
KamagraKopen.pro: Kamagra Kopen – kamagra pillen kopen
Buy Cialis online: cialis without a doctor prescription – cheapest cialis
http://tadalafileasybuy.com/# Generic Cialis price
https://kamagrakopen.pro/# kamagra pillen kopen
https://kamagrakopen.pro/# kamagra gel kopen
kamagra jelly kopen [url=https://kamagrakopen.pro/#]kamagra 100mg kopen[/url] Kamagra
kamagra 100mg kopen: kamagra 100mg kopen – Officiele Kamagra van Nederland
A big thank you for your blog article.Much thanks again. Keep writing.
I read this article completely regarding the difference of most up-to-date and previous technologies, it’s remarkable article.
kamagra pillen kopen [url=https://kamagrakopen.pro/#]Kamagra[/url] kamagra gel kopen
kamagra gel kopen: kamagra pillen kopen – kamagra kopen nederland
Say, you got a nice blog post.Really looking forward to read more. Much obliged.
There is clearly a bundle to realize about this. I feel you made certain good points in features also.
https://tadalafileasybuy.shop/# TadalafilEasyBuy.com
Kamagra: kamagra pillen kopen – Kamagra Kopen
Thank you, I’ve just been looking for info about this subject for a long time and yours is the best I’ve came upon so far. However, what in regards to the conclusion? Are you positive in regards to the source?
https://kamagrakopen.pro/# Officiele Kamagra van Nederland
Kamagra Kopen Online: Kamagra Kopen Online – Kamagra Kopen
https://generic100mgeasy.shop/# Generic100mgEasy
kamagra jelly kopen: Kamagra – kamagra pillen kopen
KamagraKopen.pro [url=https://kamagrakopen.pro/#]Kamagra[/url] kamagra kopen nederland
Im thankful for the blog post.Really thank you! Much obliged.
https://generic100mgeasy.com/# buy generic 100mg viagra online
kamagra jelly kopen: KamagraKopen.pro – kamagra jelly kopen
Officiele Kamagra van Nederland: Kamagra Kopen – Kamagra Kopen Online
¿Qué significa \”OP\” Internet y cómo se usa?
Tadalafil Easy Buy: TadalafilEasyBuy.com – Tadalafil Easy Buy
buy generic 100mg viagra online [url=https://generic100mgeasy.shop/#]buy generic 100mg viagra online[/url] Buy Viagra online cheap
https://tadalafileasybuy.shop/# Buy Tadalafil 20mg
sildenafil over the counter: buy generic 100mg viagra online – Generic100mgEasy
Your style is so unique in comparison to other people I’ve read stuff from. Many thanks for posting when you’ve got the opportunity, Guess I will just book mark this blog.
https://tadalafileasybuy.shop/# cialis without a doctor prescription
viagra without prescription: generic sildenafil – Viagra tablet online
http://generic100mgeasy.com/# Generic Viagra for sale
https://kamagrakopen.pro/# Officiele Kamagra van Nederland
Generic 100mg Easy: buy generic 100mg viagra online – buy generic 100mg viagra online
buy generic 100mg viagra online: buy generic 100mg viagra online – buy generic 100mg viagra online
пин ап зеркало – пин ап вход
buy generic 100mg viagra online [url=https://generic100mgeasy.com/#]best price for viagra 100mg[/url] Order Viagra 50 mg online
пин ап зеркало: https://pinupkz.life/
пин ап казино – пин ап казино официальный сайт
How to Swap Tokens on ApeSwap: A Complete Guide 2025
пин ап казино официальный сайт: https://pinupkz.life/
пин ап вход – пин ап вход
Tornado Cash – Best Crypto Platform for Protects Your Crypto in 2025
KamagraKopen.pro [url=https://kamagrakopen.pro/#]Kamagra Kopen Online[/url] Kamagra Kopen Online
пин ап вход: https://pinupkz.life/
пинап казино – pinup 2025
пин ап вход – пин ап казино зеркало
Фрибеты условия — как не попасайты с бесплатными фрибетамить в ловушку?
пин ап – пин ап казино официальный сайт
пин ап казино официальный сайт – пин ап казино
пин ап зеркало – пинап казино
пин ап казино официальный сайт: https://pinupkz.life/
UK non new casino sites with no gamstop casinos always deliver big wins!
pinup 2025: https://pinupkz.life/
пин ап казино официальный сайт – pinup 2025
buy generic 100mg viagra online [url=https://generic100mgeasy.shop/#]Generic100mgEasy[/url] Generic 100mg Easy
Kamagra Original: Kamagra Gel – Kamagra kaufen ohne Rezept
Kamagra Oral Jelly kaufen: Kamagra Oral Jelly kaufen – Kamagra Original
Apoteket online [url=https://apotekonlinerecept.com/#]Apotek hemleverans recept[/url] apotek pa nett
http://apotheekmax.com/# Apotheek online bestellen
http://kamagrapotenzmittel.com/# Kamagra online bestellen
Kamagra kaufen ohne Rezept: Kamagra Original – Kamagra kaufen
apotek online: apotek pa nett – apotek pa nett
This is a good blog. Keep up all the work. I too love to blog. This is great everyone sharing opinionsslot gacor
This is a good tip especially to those new to the blogosphere. Short but very accurate information… Appreciate your sharing this one. A must read article!
http://apotekonlinerecept.com/# apotek online recept
https://kamagrapotenzmittel.com/# Kamagra Original
Really informative article.Really thank you! Keep writing.
Beste online drogist: Beste online drogist – Beste online drogist
https://apotheekmax.shop/# Online apotheek Nederland met recept
https://apotheekmax.com/# online apotheek
Wow, great article.Thanks Again. Cool.
https://apotheekmax.shop/# de online drogist kortingscode
apotek pa nett: Apotek hemleverans idag – apotek online
Apotek hemleverans idag: Apotek hemleverans idag – Apotek hemleverans idag
apotek pa nett [url=https://apotekonlinerecept.com/#]Apotek hemleverans idag[/url] Apoteket online
Thanks-a-mundo for the post. Really Great.
Кейсы CS2 с анимацией — это новый уровень!
https://mozillabd.science/wiki/User:NoreenHuntsman
CS:GO кейсы — это вечная надежда на лучшее!
https://championsleage.review/wiki/Cs2case_58H
http://apotheekmax.com/# Apotheek Max
https://apotheekmax.com/# Apotheek Max
https://apotekonlinerecept.com/# apotek online recept
Kamagra Oral Jelly kaufen: Kamagra Oral Jelly – Kamagra Oral Jelly kaufen
I really like and appreciate your blog. Much obliged.
https://apotekonlinerecept.com/# apotek online
Kamagra kaufen: Kamagra Oral Jelly kaufen – Kamagra kaufen ohne Rezept
Apoteket online [url=https://apotekonlinerecept.shop/#]Apotek hemleverans idag[/url] apotek online
http://apotheekmax.com/# online apotheek
de online drogist kortingscode: de online drogist kortingscode – Online apotheek Nederland met recept
http://apotheekmax.com/# Betrouwbare online apotheek zonder recept
iZiSwap updates
Apotek hemleverans idag: Apotek hemleverans idag – Apoteket online
https://apotekonlinerecept.com/# apotek online recept
Kamagra Gel: Kamagra online bestellen – Kamagra kaufen ohne Rezept
https://apotheekmax.com/# de online drogist kortingscode
Online apotheek Nederland met recept: Online apotheek Nederland zonder recept – Apotheek Max
ApotheekMax: Online apotheek Nederland met recept – ApotheekMax
What a material of un-ambiguity and preserveness ofprecious experience concerning unpredicted emotions.
https://kamagrapotenzmittel.shop/# Kamagra Original
https://apotheekmax.shop/# Apotheek online bestellen
online canadian pharmacy reviews: GoCanadaPharm – canadian pharmacy ratings
https://gocanadapharm.com/# canadian pharmacy india
www india pharm: top 10 pharmacies in india – www india pharm
Agb Mexico Pharm [url=https://agbmexicopharm.com/#]Agb Mexico Pharm[/url] Agb Mexico Pharm
reputable indian pharmacies: www india pharm – online pharmacy india
Alibarbar Ingot’s puff count is insane—perfect for heavy vapers.
Gunnpod Evo
https://gocanadapharm.com/# canadian pharmacy no rx needed
safe reliable canadian pharmacy: cheap canadian pharmacy – canadian pharmacy tampa
mexican drugstore online: mexican border pharmacies shipping to usa – Agb Mexico Pharm
Online casinos should free—test run!
Feel free to visit my site; https://haze-growroom.de.tl/Forum/topic-10420-1-Book-of-Ra.htm
http://agbmexicopharm.com/# Agb Mexico Pharm
pharmacies in mexico that ship to usa: buying prescription drugs in mexico online – pharmacies in mexico that ship to usa
canadian pharmacy online store: GoCanadaPharm – canadian pharmacy ratings
mexican rx online: Agb Mexico Pharm – Agb Mexico Pharm
I’ve never had a bad experience with Polygon Bridge.
mexico pharmacies prescription drugs [url=https://agbmexicopharm.shop/#]Agb Mexico Pharm[/url] Agb Mexico Pharm
https://wwwindiapharm.shop/# top online pharmacy india
canadapharmacyonline: GoCanadaPharm – canadian pharmacy scam
canada drug pharmacy: GoCanadaPharm – canadian online pharmacy
Agb Mexico Pharm: Agb Mexico Pharm – mexico pharmacies prescription drugs
reliable canadian pharmacy [url=https://gocanadapharm.shop/#]go canada pharm[/url] canadapharmacyonline
http://agbmexicopharm.com/# Agb Mexico Pharm
www india pharm: www india pharm – reputable indian online pharmacy
Online medicine order: india pharmacy – www india pharm
www india pharm: buy prescription drugs from india – www india pharm
http://gocanadapharm.com/# canadian 24 hour pharmacy
www india pharm: www india pharm – online pharmacy india
Agb Mexico Pharm [url=https://agbmexicopharm.com/#]mexican mail order pharmacies[/url] mexico drug stores pharmacies
One of the standout features of Polygon Bridge is its robust security measures. I’ve conducted numerous transactions with peace of mind, knowing that my assets are safe. Their commitment to transparency and user support really sets them apart!
canadian medications: canadian world pharmacy – canadian pharmacy service
Обзор БК-контор с бонусами при регистрации на рынке РФ
БК конторы с бонусом при регистрации – обзор рынка
Сегодня ставки на спорт
стали неотъемлемой частью жизни
миллионов россиян. Выбор надежного партнера для заключения пари – важнейший шаг на пути к успеху.
Одним из ключевых факторов, влияющих на привлекательность букмекерской конторы, являются стартовые бонусы для новых игроков.
Эти поощрения могут значительно повысить ваши шансы на
выигрыш, позволяя безрисково опробовать возможности платформы.
В данном материале мы проанализируем наиболее интересные предложения от ведущих букмекерских контор России, оценив
их преимущества и недостатки.
Вы узнаете, где можно получить максимальные приветственные
бонусы и на каких условиях они предоставляются.
Это поможет вам сделать обоснованный выбор
при регистрации в новой букмекерской конторе и приступить
к ставкам на выгодных условиях.
Наша цель – предоставить
вам детальную и объективную информацию, которая позволит принять взвешенное решение.
Мы уверены, что после ознакомления
с данным материалом вы сможете найти идеального партнера для заключения пари на спортивные события с максимальной выгодой для себя.
Анализ наиболее привлекательных предложений от букмекеров
на российском рынке
При выборе оператора для ставок
особое внимание стоит уделить предложениям, которые направлены на привлечение
новых клиентов. В 2023 году на российском сегменте выделяется
несколько компаний с заманчивыми
акциями.
1. Бонус на первый депозит. Многие
организации предлагают увеличить сумму первого пополнения счет на 100% или более.
Например, клиент, пополнивший счет на 5 000 рублей, получит
ещё 5 000 в виде кредита для ставок.
Это позволяет сделать первые шаги в ставках более уверенно.
2. Фрибеты. Некоторые букмекеры выдают фрибеты – бесплатные ставки, которые можно использовать в течение ограниченного времени.
Размер таких предложений может варьироваться от 1 000 до 3 000 рублей.
Применение фрибетов позволяет тестировать
стратегию без потери собственных средств.
3. Кэшбэк. Некоторые компании внедрили кэшбэк-системы, возвращающие определённый процент от проигранных ставок.
Например, может предоставляться
возврат до 10% от суммы проигрышей
за неделю. Это обеспечит дополнительный уровень безопасности и смягчит убытки.
4. Партнёрские программы.
Некоторые букмекеры предлагают выгодные
условия для тех, кто привлекает
новых клиентов. В зависимости
от модели, комиссионные могут достигать 30% от прибыли игрока, что делает такие предложения весьма прибыльными.
5. Дополнительные акции.
Сезонные мероприятия, такие как чемпионаты или важные спортивные события,
сопровождаются стимулирующими программами.
Например, в дни крупных матчей ставки могут давать повышенный коэффициент или
дополнительные бесплатные ставки.
Это привлекает внимание и создает возможность для увеличения выигрышей.
В итоге, анализ наиболее интересных
предложений позволяет выбрать наиболее
выгодные условия для ставок.
Важно внимательно ознакомиться с правилами и
условиями акций, чтобы избежать неприятных сюрпризов.
Практические рекомендации по выбору букмекерской
конторы с привлекательным предложением для начинающих
Перед тем как сделать выбор, стоит обратить внимание на лицензию.
Убедитесь, что компания имеет официальное разрешение на осуществление деятельности в России.
Это гарантирует защиту ваших интересов и безопасность
транзакций.
Сравните предлагаемые условия.
Обратите внимание на размер стартового предложения.
Некоторые компании могут предложить более выгодные условия, чем другие.
Проведите анализ, чтобы выбрать наиболее привлекательное
предложение.
Чтение отзывов пользователей –
важный аспект. Найдите информацию о том, как компания справляется с выплатами и какие сложности возникают у клиентов.
Форумы и специализированные сайты могут помочь получить актуальные мнения.
Обратите внимание на качество службы поддержки.
Быстрая и компетентная помощь может оказаться решающей в сложных ситуациях.
Протестируйте различные способы связи, чтобы понять,
насколько оперативно реагируют
на запросы.
Не забывайте о мобильной версии сайта или приложении.
Удобный интерфейс и возможность делать ставки с мобильных устройств могут
значительно улучшить опыт использования платформы.
Рассмотрите дополнительные акции.
Компании часто предлагают разные
программы для постоянных клиентов.
Это могут быть бездепозитные предложения или кэшбэк, что
делает работу с платформой более выгодной.
И наконец, определите свои цели
и стиль игры. Для одних малый стартовый капитал и низкие риски – это главный приоритет, для
других – высокий потенциал выигрыша.
Выбирайте платформу, которая соответствует вашим
потребностям и ожиданиям.
Also visit my site: приветственный бонус
Лучшие букмекерские бонусы
для ставок на спорт
Лучшие бонусы в рейтинг букмекерове букмекеров
Для заядлых болельщиков, активно следящих за развитием спортивных событий, особую ценность представляют выгодные предложения от операторов
приёма ставок. Эти предложения открывают широкие возможности для увеличения доходов
от увлекательного хобби. Однако отыскать действительно привлекательные варианты
бонусов среди множества доступных вариантов бывает непросто.
Мы поможем вам сориентироваться в разнообразии предложений и
выбрать оптимальные бонусы, максимально соответствующие
вашим интересам и потребностям.
Щедрые приветственные подарки
– один из наиболее популярных видов бонусов среди новых игроков.
Они позволяют уверенно начать игру с дополнительными средствами на счету и опробовать различные стратегии ставок без риска потери собственных денег.
Воспользовавшись такими поощрительными программами,
вы сможете получить существенные преимущества над теми, кто пренебрегает бонусами.
Кроме того, опытные любители азартных состязаний высоко ценят
регулярные акции и промо-предложения от операторов ставок.
Эти предложения нередко включают в себя дополнительные множители
коэффициентов на определённые события, бесплатные ставки
и другие выгодные условия.
Регулярное отслеживание актуальных акций способно многократно приумножить ваш игровой банк.
Бонусы на первый депозит от ведущих игровых операторов
Если вы только начинаете свой путь в мире ставок,
стоит обратить внимание на привлекательные предложения
по бонусам на первый взнос от признанных букмекеров.
Такие поощрения могут значительно увеличить ваш стартовый капитал и дать
возможность попробовать свои силы в ставках практически без риска.
Одним из востребованных бонусов является 100% надбавка к первому пополнению счета.
Например, известный оператор предлагает новым клиентам удвоить их первый депозит
до 10 000 рублей. Таким образом, внеся 5 000 рублей, вы получите еще 5
000 бонусных средств для совершения ставок.
Другие игровые площадки могут предоставлять фрибеты – бесплатные
ставки на определенную сумму.
Такие бонусы позволяют опробовать платформу и ознакомиться с линией
событий без риска потерять собственные деньги.
Также стоит обратить внимание на
бонусы, начисляемые за регистрацию без внесения депозита.
Подобные поощрения дают возможность начать делать ставки сразу после
создания учетной записи.
Выбирая букмекера, обращайте внимание на размер, условия активации и отыгрыша
бонусов. Это позволит максимально эффективно
использовать предложения и приумножить свой игровой банк.
Акции и промокоды с увеличенными множителями
Операторы пари предлагают акции с повышенными котировками на отдельные поединки или
экспрессы. Это позволяет получить больше выигрыша
при той же вероятности. Например, “Лига Пари” регулярно
проводит “Экспресс дня” с увеличенным
итоговым множителем на предложенные комбинации исходов.
Условия акции требуют соответствия экспресса заданным событиям и коэффициентам.
Промокоды, распространяемые через партнерские ресурсы
или рассылки, также часто дают право на увеличенные
множители. “Фонбет” может
предлагать индивидуальные промокоды на повышение котировки
на конкретный матч, доступные зарегистрированным пользователям.
Важно внимательно изучать правила акций с увеличенными множителями.
Некоторые операторы пари устанавливают ограничения по максимальной сумме пари, участвующей в акции, или по виду пари (только ординары или экспрессы).
“Бетсити”, например, может устанавливать лимиты на максимальный выигрыш
по пари с повышенным множителем.
Сравнение предложений от разных платформ – ключевой шаг.
Одна платформа может предлагать увеличение котировки на футбол, а другая – на теннис.
Анализируйте, какое мероприятие представляет больший интерес, и выбирайте
наиболее выгодное предложение.
Обратите внимание на условия отыгрыша потенциального выигрыша, полученного с использованием увеличенных множителей.
“Винлайн” иногда требует отыгрыша разницы между стандартным и увеличенным коэффициентом.
Agb Mexico Pharm: medication from mexico pharmacy – Agb Mexico Pharm
reputable mexican pharmacies online: mexico pharmacies prescription drugs – medicine in mexico pharmacies
reliable canadian pharmacy: go canada pharm – canadian pharmacy in canada
Clom Fast Pharm: cost of cheap clomid without a prescription – can i get clomid pills
AmOnlinePharm: order amoxicillin 500mg – prescription for amoxicillin
zithromax price south africa [url=http://zithpharmonline.com/#]zithromax 500 mg lowest price pharmacy online[/url] ZithPharmOnline
prednisone 1 mg tablet: Pred Pharm Net – Pred Pharm Net
can i order generic clomid pills: where can i get generic clomid without a prescription – where buy cheap clomid pill
prednisone purchase canada: prednisone price south africa – Pred Pharm Net
https://amonlinepharm.com/# amoxicillin no prescipion
generic amoxil 500 mg: generic amoxicillin over the counter – amoxicillin generic brand
AmOnlinePharm: cost of amoxicillin prescription – AmOnlinePharm
http://predpharmnet.com/# Pred Pharm Net
Clom Fast Pharm [url=https://clomfastpharm.com/#]Clom Fast Pharm[/url] Clom Fast Pharm
canadian online pharmacy prednisone: Pred Pharm Net – Pred Pharm Net
ZithPharmOnline: ZithPharmOnline – where can i purchase zithromax online
https://predpharmnet.com/# Pred Pharm Net
AmOnlinePharm: AmOnlinePharm – amoxicillin without a doctors prescription
amoxicillin 250 mg: AmOnlinePharm – AmOnlinePharm
Pred Pharm Net: Pred Pharm Net – Pred Pharm Net
https://predpharmnet.shop/# Pred Pharm Net
where buy cheap clomid without insurance: Clom Fast Pharm – how to get generic clomid price
wow, awesome post.Thanks Again. Really Cool.
Lisin Express: Lisin Express – Lisin Express
AmOnlinePharm: amoxicillin generic brand – amoxicillin 500 mg tablet price
http://zithpharmonline.com/# zithromax 250 price
how to get generic clomid without prescription: Clom Fast Pharm – get generic clomid without rx
Lisin Express: Lisin Express – Lisin Express
lisinopril 60 mg: Lisin Express – lisinopril 20 mg mexico
http://amonlinepharm.com/# how to buy amoxicillin online
A round of applause for your article post. Much obliged.
ZithPharmOnline: ZithPharmOnline – ZithPharmOnline
AmOnlinePharm: amoxicillin 500mg without prescription – AmOnlinePharm
https://lisinexpress.com/# prinivil price
Clom Fast Pharm: Clom Fast Pharm – Clom Fast Pharm
Clom Fast Pharm: buy clomid without prescription – Clom Fast Pharm
Thanks for the blog article.Really thank you! Keep writing.
how can i get clomid tablets: how can i get cheap clomid without insurance – Clom Fast Pharm
If I issue my articles to my school document are they copyrighted or else do I have several ownership greater than them?
Muchos Gracias for your blog article.
ZithPharmOnline: ZithPharmOnline – ZithPharmOnline
AmOnlinePharm: AmOnlinePharm – buy amoxicillin online uk
prednisone 5mg capsules [url=http://predpharmnet.com/#]prednisone 10 mg brand name[/url] buy prednisone 10 mg
AmOnlinePharm: AmOnlinePharm – AmOnlinePharm
Thanks designed for sharing such a pleasant idea, paragraph is good, thats why i have read it fully
http://amonlinepharm.com/# amoxicillin 500mg for sale uk
apeswap $banana token
apeswap roadmap
apeswap web3
ZithPharmOnline: ZithPharmOnline – ZithPharmOnline
lisinopril 40 mg price in india: lisinopril cost – order lisinopril without a prescription
http://casibom1st.com/# en Г§ok kazandД±ran bahis siteleri
yasal kumar siteleri: casibom giris – canlД± casino bahis siteleri casibom1st.com
apeswap staking
sweet bonanza giris [url=https://sweetbonanza1st.com/#]sweet bonanza oyna[/url] sweet bonanza oyna sweetbonanza1st.com
ed pharmacy canadian pharmacy online – express scripts pharmacy
sweet bonanza: sweet bonanza giris – sweet bonanza oyna sweetbonanza1st.shop
ordiswap $ordi
bahis siteleri 2024: gГјvenilir oyun alma siteleri – casino siteleri 2025 casinositeleri1st.com
ordiswap tokenomics
ordiswap founder
Thanks on your marvelous posting! I actually enjoyed reading it,you’re a great author. I will ensure that I bookmark your blog and may come back atsome point. I want to encourage you to ultimatelycontinue your great job, have a nice day!
https://casinositeleri1st.shop/# en yeni bet siteleri
apartments for rent long island apartments for rent boca raton highpointe apartments
sweet bonanza demo: sweet bonanza yorumlar – sweet bonanza demo sweetbonanza1st.shop
sweet bonanza giris: sweet bonanza giris – sweet bonanza slot sweetbonanza1st.shop
sweet bonanza 1st: sweet bonanza slot – sweet bonanza sweetbonanza1st.shop
sweet bonanza: sweet bonanza oyna – sweet bonanza giris sweetbonanza1st.shop
canli bahis siteleri: casibom giris – popГјler bahis casibom1st.com
arbswap defi tools
arbswap launch
arbswap arbitrum
deneme bonusu veren siteler: deneme bonusu veren siteler – slot casino siteleri casinositeleri1st.com
Im obliged for the blog article.Really thank you! Great.
Thanks again for the article. Will read on…
en iyi deneme bonusu veren siteler: casibom resmi – jav siteleri casibom1st.com
canlД± bahis siteleri: casibom resmi – canlД± casino deneme bonusu veren siteler casibom1st.com
sweet bonanza giris [url=http://sweetbonanza1st.com/#]sweet bonanza oyna[/url] sweet bonanza demo sweetbonanza1st.com
wow, awesome article post.
arbswap arbitrum
cbridge bsc
cbridge defi
lisansl? casino siteleri: lisansl? casino siteleri – slot casino siteleri casinositeleri1st.com
deneme bonusu veren siteler: deneme bonusu veren siteler – casino siteleri casinositeleri1st.com
como bakery yorumlarД±: casibom giris – bilinmeyen bahis siteleri casibom1st.com
tГјm bet siteleri: casibom resmi – betler casibom1st.com
sweet bonanza yorumlar: sweet bonanza 1st – sweet bonanza 1st sweetbonanza1st.shop
deneme bonusu veren siteler [url=https://casinositeleri1st.com/#]deneme bonusu veren siteler[/url] casino siteleri casinositeleri1st.shop
http://casinositeleri1st.com/# guvenilir casino siteleri
100 tl deneme bonus veren bahis siteleri: casibom guncel adres – para kazandiran kumar oyunlarД± casibom1st.com
casinonaxi: casibom giris adresi – en yeni bet siteleri casibom1st.com
sweet bonanza oyna: sweet bonanza giris – sweet bonanza 1st sweetbonanza1st.shop
Really enjoyed this blog article.Thanks Again. Really Great.
en iyi kumar sitesi: casibom guncel giris – gore siteler casibom1st.com
sweet bonanza 1st [url=http://sweetbonanza1st.com/#]sweet bonanza 1st[/url] sweet bonanza giris sweetbonanza1st.com
Im obliged for the blog post. Cool.
http://sweetbonanza1st.com/# sweet bonanza siteleri
oyun dene: casibom guncel adres – deneme bonusu veren bahis siteleri 2025 casibom1st.com
gore siteler: casibom guncel giris – canlД± bahis oyunlarД± casibom1st.com
sweet bonanza 1st: sweet bonanza siteleri – sweet bonanza 1st sweetbonanza1st.shop
cbridge polygon
bridge crypto with cbridge
cbridge network
casino siteleri: guvenilir casino siteleri – casino siteleri casinositeleri1st.com
deneme bonusu veren siteler: guvenilir casino siteleri – deneme bonusu veren siteler casinositeleri1st.com
Insolvency Practitioners
https://usmexpharm.shop/# usa mexico pharmacy
usa mexico pharmacy: п»їbest mexican online pharmacies – usa mexico pharmacy
UsMex Pharm: certified Mexican pharmacy – usa mexico pharmacy
mexican pharmacy: certified Mexican pharmacy – Mexican pharmacy ship to USA
http://usmexpharm.com/# mexican mail order pharmacies
Us Mex Pharm: mexican online pharmacies prescription drugs – pharmacies in mexico that ship to usa
USMexPharm: UsMex Pharm – Us Mex Pharm
UsMex Pharm [url=https://usmexpharm.shop/#]certified Mexican pharmacy[/url] usa mexico pharmacy
Us Mex Pharm: mexico pharmacies prescription drugs – mexican pharmacy
http://usmexpharm.com/# USMexPharm
reputable mexican pharmacies online: mexican border pharmacies shipping to usa – buying prescription drugs in mexico
certified Mexican pharmacy: mexican pharmacy – USMexPharm
Mexican pharmacy ship to USA [url=http://usmexpharm.com/#]Mexican pharmacy ship to USA[/url] USMexPharm
Mexican pharmacy ship to USA: usa mexico pharmacy – certified Mexican pharmacy
usa mexico pharmacy: mexican mail order pharmacies – UsMex Pharm
https://usmexpharm.com/# certified Mexican pharmacy
Mexican pharmacy ship to USA: USMexPharm – Mexican pharmacy ship to USA
dexguru token analytics
dexguru
Mexican pharmacy ship to USA: mexican pharmacy – Mexican pharmacy ship to USA
mexican pharmacy [url=http://usmexpharm.com/#]Mexican pharmacy ship to USA[/url] Mexican pharmacy ship to USA
Бытовая техника NEFF: инновации,
стиль и немецкое качество
Немецкий бренд NEFF, основанный в 1877 году, уже почти
полтора века остается синонимом
качества, инноваций и изысканного дизайна в мире
бытовой техники. Специализируясь на встраиваемых решениях премиум-класса, NEFF предлагает широкий ассортимент приборов,
которые превращают рутинные домашние дела в удовольствие,
а кухню — в пространство для творчества.
В этой статье мы расскажем, чем
выделяется техника NEFF, какие категории приборов она включает и почему бренд завоевал доверие миллионов пользователей по всему миру.
История и философия бренда
NEFF был основан Карлом Андреасом Неффом
в городе Бреттен, Германия. Начав с производства угольных
печей, компания быстро перешла к
созданию передовых решений для дома.
Сегодня NEFF входит в состав концерна BSH
Hausgeräte GmbH, но сохраняет свою уникальную идентичность, ориентированную на кулинарное творчество и функциональность.
Философия бренда строится вокруг
идеи вдохновлять пользователей.
NEFF не просто создает технику — он предлагает инструменты для реализации идей, будь то приготовление сложного ужина или уход за домом.
Слоган бренда — «Готовьте с
удовольствием» — отражает стремление сделать
процесс работы с техникой интуитивно понятным и увлекательным.
Ассортимент бытовой техники NEFF
NEFF специализируется на встраиваемой технике,
которая гармонично интегрируется
в любой интерьер. Ассортимент бренда включает несколько ключевых
категорий, каждая из которых
отличается инновационными технологиями
и продуманным дизайном.
1. Духовые шкафы
Духовые шкафы NEFF — это сердце ассортимента бренда.
Они оснащены уникальными функциями,
такими как:
CircoTherm®: система равномерного распределения горячего воздуха, позволяющая готовить несколько блюд одновременно без смешивания запахов.
Slide&Hide®: полностью убирающаяся дверца, которая экономит пространство и упрощает доступ к блюдам.
VarioSteam®: функция добавления пара для сохранения сочности
и текстуры блюд.
Модели 2023–2025 годов предлагают интеллектуальное управление
через приложение Home Connect, которое позволяет контролировать процесс приготовления
удаленно и получать рекомендации по
рецептам.
2. Варочные панели
Варочные панели NEFF представлены газовыми, электрическими и индукционными моделями.
Индукционные панели с технологией FlexInduction позволяют
гибко использовать зоны нагрева,
адаптируя их под посуду любого размера.
Управление осуществляется через интуитивно понятную кнопку TwistPad® Fire,
которая заменяет традиционные переключатели
и обеспечивает точную настройку.
3. Посудомоечные машины
Посудомоечные машины NEFF сочетают экономичность и высокую эффективность.
Технология DoorOpen Assist позволяет открывать дверцу легким нажатием, что особенно удобно для кухонь без ручек.
Функция Time Light проецирует время до конца цикла на пол, а модели с
загрузкой до 14 комплектов посуды идеально подходят для больших семей.
4. Холодильники и морозильники
Холодильники NEFF отличаются продуманной эргономикой и функциями сохранения свежести продуктов.
Зона FreshSafe поддерживает оптимальную температуру и влажность,
а технологии суперохлаждения и суперзаморозки
обеспечивают длительное хранение без потери качества.
5. Вытяжки
Вытяжки NEFF — это сочетание мощности и эстетики.
Модели шириной до 90 см подходят
для больших варочных панелей, а варианты с
выдвижным экраном идеально вписываются в компактные кухни.
Технология CleanAir эффективно устраняет
запахи, обеспечивая комфорт в помещении.
6. Микроволновые печи и пароварки
Микроволновые печи NEFF объемом 20–25 литров оснащены грилем
и автоматическими программами, что делает их универсальными помощниками.
Пароварки поддерживают приготовление в стиле Sous-Vide,
сохраняя вкус и пользу продуктов.
7. Стиральные машины
Стиральные машины NEFF выделяются уникальной функцией
Time Light, которая проецирует информацию о стирке на пол.
Инверторные двигатели гарантируют тихую работу
и долговечность, а программы
для деликатных тканей обеспечивают бережный уход.
8. Кофемашины и аксессуары
Встраиваемые кофемашины NEFF позволяют наслаждаться профессиональным кофе дома.
Они поддерживают приготовление
эспрессо, капучино и других напитков с настройкой крепости и объема.
Аксессуары, такие как фильтры для воды и средства для ухода, продлевают срок службы техники.
Инновации и технологии
NEFF постоянно внедряет новые решения, чтобы упростить жизнь пользователей:
Home Connect: приложение для удаленного управления
техникой, синхронизации рецептов и диагностики состояния приборов.
Pyrolytic Cleaning: система пиролитической самоочистки для духовых шкафов,
которая превращает загрязнения в пепел.
EfficientSilentDrive: тихие и энергоэффективные моторы в вытяжках и
посудомоечных машинах.
Эти технологии не только повышают удобство,
но и способствуют экономии ресурсов, что делает технику NEFF экологически ответственной.
Дизайн и интеграция
Встраиваемая техника NEFF разработана так, чтобы стать частью кухонного гарнитура.
Использование нержавеющей стали, стекла и стеклокерамики
придает приборам элегантный вид, который подходит
для стилей от минимализма
до хай-тека. Устройства гармонично сочетаются друг с
другом, позволяя создавать комплекты из варочной панели, духового шкафа,
вытяжки и других приборов.
Преимущества техники NEFF
Немецкое качество: производство на заводе в
Бреттене гарантирует надежность
и долговечность.
Инновации: NEFF задает стандарты в отрасли, внедряя функции, которые позже становятся трендами.
Удобство: интуитивное управление и
продуманная эргономика делают технику доступной для всех.
Эстетика: стильный дизайн превращает приборы в украшение кухни.
Гарантия и сервис: официальные дилеры предлагают гарантию до
12 месяцев и доступ к оригинальным
комплектующим до 10 лет.
Почему выбирают NEFF?
NEFF выбирают те, кто ценит комфорт, функциональность и возможность экспериментировать.
Бренд идеально подходит для кулинаров, которые хотят раскрыть свой потенциал, и
для тех, кто ищет надежные решения для
дома. Отзывы пользователей
подчеркивают долговечность техники и ее способность упрощать повседневные
задачи.
https://polyamory.wiki/w/User:AdrienneMistry
Mexican pharmacy ship to USA: USMexPharm – Us Mex Pharm
mexican pharmacy: mexico drug stores pharmacies – USMexPharm
Bookmarking this for future reference—pure gold.
http://usmexpharm.com/# Mexican pharmacy ship to USA
usa mexico pharmacy: certified Mexican pharmacy – mexican pharmacy
mexican pharmacy [url=https://usmexpharm.com/#]mexican pharmacy[/url] Us Mex Pharm
mexican pharmacy: mexican pharmacy – mexican pharmacy
mexican pharmacy: USMexPharm – Mexican pharmacy ship to USA
https://usmexpharm.com/# Mexican pharmacy ship to USA
USA India Pharm: USA India Pharm – UsaIndiaPharm
USA India Pharm: USA India Pharm – buy prescription drugs from india
I cannot thank you enough for the blog post.Really looking forward to read more.
polygon bridge erc20
best polygon bridge
п»їlegitimate online pharmacies india: india online pharmacy – USA India Pharm
This is what true DeFi interoperability looks like.
buy medicines online in india [url=https://usaindiapharm.com/#]india pharmacy mail order[/url] Online medicine order
http://usaindiapharm.com/# top 10 online pharmacy in india
UsaIndiaPharm: cheapest online pharmacy india – USA India Pharm
Awesome blog article.Really looking forward to read more. Much obliged.
Профессиональный сервисный центр по ремонту бытовой техники с выездом на дом.
Мы предлагаем:сервисные центры в москве
Наши мастера оперативно устранят неисправности вашего устройства в сервисе или с выездом на дом!
best online pharmacy india: USA India Pharm – USA India Pharm
portal bridge
UsaIndiaPharm [url=https://usaindiapharm.com/#]UsaIndiaPharm[/url] top 10 online pharmacy in india
UsaIndiaPharm: india online pharmacy – india pharmacy
Enjoyed every bit of your blog article.Much thanks again. Will read on…
https://usaindiapharm.shop/# online pharmacy india
UsaIndiaPharm: USA India Pharm – UsaIndiaPharm
indian pharmacy online: UsaIndiaPharm – indian pharmacies safe
https://usaindiapharm.shop/# UsaIndiaPharm
USA India Pharm: pharmacy website india – п»їlegitimate online pharmacies india
I value the article. Cool.
Helpful breakdown of how to use Polygon the smart way.
UsaIndiaPharm: USA India Pharm – buy prescription drugs from india
UsaIndiaPharm: buy medicines online in india – buy prescription drugs from india
http://usaindiapharm.com/# cheapest online pharmacy india
apeswap vs pancakeswap
india online pharmacy: UsaIndiaPharm – USA India Pharm
Thanks for the post.Much thanks again. Really Cool.
USA India Pharm: USA India Pharm – Online medicine order
best india pharmacy [url=https://usaindiapharm.shop/#]USA India Pharm[/url] top 10 online pharmacy in india
http://usaindiapharm.com/# USA India Pharm
online shopping pharmacy india: cheapest online pharmacy india – indianpharmacy com
Very good article.Much thanks again. Great.
iZiSwap support
USA India Pharm: USA India Pharm – top 10 pharmacies in india
https://usaindiapharm.shop/# reputable indian online pharmacy
USA India Pharm: top online pharmacy india – Online medicine order
USA India Pharm: online pharmacy india – USA India Pharm
india online pharmacy [url=https://usaindiapharm.com/#]USA India Pharm[/url] top 10 pharmacies in india
indian pharmacy: UsaIndiaPharm – USA India Pharm
Major thanks for the article.Much thanks again.
Wish I had this guide when I first started farming.
https://usaindiapharm.shop/# USA India Pharm
USA India Pharm: buy prescription drugs from india – USA India Pharm
Major thanks for the article post.Really looking forward to read more. Want more.
USA India Pharm: UsaIndiaPharm – india online pharmacy
https://usaindiapharm.shop/# top 10 online pharmacy in india
UsaIndiaPharm: indian pharmacy paypal – indian pharmacy paypal
top 10 pharmacies in india: USA India Pharm – п»їlegitimate online pharmacies india
Link Tải F79
I enjoy reading through an article that will make people think. Also, many thanks for allowing for me to comment! Amitie Franky Kathy
Rhinobridge just works.
https://usaindiapharm.shop/# indian pharmacy
USA India Pharm: top online pharmacy india – UsaIndiaPharm
UsaIndiaPharm: india pharmacy – п»їlegitimate online pharmacies india
buy prescription drugs from india: indian pharmacy – online pharmacy india
USA India Pharm [url=https://usaindiapharm.com/#]UsaIndiaPharm[/url] USA India Pharm
Very informative article post.Thanks Again. Will read on…
https://usaindiapharm.com/# india online pharmacy
Thank you ever so for you article post.Really looking forward to read more. Really Cool.
http://usacanadapharm.com/# USACanadaPharm
usa canada pharm: my canadian pharmacy review – canadian pharmacy
the canadian drugstore [url=https://usacanadapharm.com/#]USACanadaPharm[/url] USACanadaPharm
USACanadaPharm: USACanadaPharm – USACanadaPharm
Thanks so much for the post.
These are actually great ideas in on the topic of blogging.You have touched some fastidious points here.Any way keep up wrinting.
https://usacanadapharm.com/# best rated canadian pharmacy
canadian pharmacy antibiotics: usa canada pharm – usa canada pharm
Wow, great blog article.Thanks Again. Want more.
usa canada pharm [url=https://usacanadapharm.com/#]reliable canadian pharmacy[/url] usa canada pharm
usa canada pharm: best canadian pharmacy online – legal to buy prescription drugs from canada
USACanadaPharm: USACanadaPharm – USACanadaPharm
http://usacanadapharm.com/# USACanadaPharm
canadian pharmacy: USACanadaPharm – usa canada pharm
USACanadaPharm: canadian pharmacy – USACanadaPharm
https://usacanadapharm.com/# canada pharmacy online
canadian pharmacies compare: canadian pharmacy online ship to usa – canada pharmacy 24h
Appreciate you sharing, great blog.Really looking forward to read more. Awesome.
monitoring on tamoxifen tamoxifen side effects tamoxifen for postmenopausal
http://usacanadapharm.com/# cheap canadian pharmacy
I’m really impressed with your writing skills as well as with the layout on your blog.Is this a paid theme or did you modify it yourself? Anyway keep up the excellent quality writing, it’s rare to see a great blog like this one these days.
canadian online drugstore: canadian family pharmacy – USACanadaPharm
I loved your post.Really thank you! Want more.
USACanadaPharm [url=https://usacanadapharm.com/#]usa canada pharm[/url] safe online pharmacies in canada
usa canada pharm: reputable canadian pharmacy – USACanadaPharm
usa canada pharm: USACanadaPharm – USACanadaPharm
Selecting Online Casinos for High RTP Games
Selecting Online Casinos with High RTP Game Choices
Engaging with electronic gaming venues that feature impressive
payout percentages can significantly enhance the overall experience of players.
Not every establishment offers the same level of return to player (RTP) rates, thus understanding
how to identify those that truly deliver is important.
Various aspects play a role in this evaluation, including game selection, software providers,
and the credibility of the operators.
First and foremost, assess the offerings of various
gaming platforms. Titles that boast higher RTPs often include classic slot machines or table games like blackjack.
By prioritizing venues that highlight such options, players can improve their likelihood
of favorable returns. Additionally, seeking out reviews and ratings from experienced
users can provide insight into the performance and reliability of gaming options available on different sites.
Moreover, examining the software developers responsible for the games is a key factor.
Renowned companies have established themselves through
a reputation for quality and transparency regarding RTP figures.
Their games not only tend to have better mechanics but also offer more reliable odds, aiding players in making informed choices.
Always verify that the venue lists this information clearly and that it
aligns with regulatory standards for fairness.
Identifying Reputable Platforms with Elevated Return Rates
To discover trustworthy platforms offering elevated return percentages,
scrutinizing licensing and regulatory compliance is
paramount. Look for establishments licensed by reputable
authorities such as the UK Gambling Commission or
the Malta Gaming Authority. These bodies enforce stringent
standards, ensuring fair play and player protection.
Evaluating user feedback is another vital step. Online forums and review websites often reveal insights from actual players regarding their experiences.
Look for patterns in feedback, especially concerning payout speed and
reliability. High ratings in these areas can indicate a
reputable provider.
Additionally, check for independent auditing of payout percentages.
Organizations like eCOGRA or iTech Labs conduct tests and publish reports on game fairness.
A seal of approval from these auditors can serve as a strong endorsement of
the establishment’s integrity.
Another factor to consider is the variety of options available.
Platforms that offer a wider selection of titles with known high return rates often prioritize transparency and
player satisfaction. It’s beneficial to seek those that not only showcase these games but also provide detailed information regarding their payout rates.
Lastly, promotional offerings such as bonuses and loyalty programs can also indicate a
providers’ commitment to player experience. However, ensure
that terms and conditions related to bonuses are clear and fair, as misleading offers can detract from the overall value.
Evaluating Game Selection and Provider Quality for Optimal RTP
Analyzing the assortment of titles and the reputation of manufacturers is key to identifying platforms
that feature favorable return-to-player percentages.
Begin by examining the variety of games offered, ensuring a rich
mix of slots, table options, and specialty titles. A wider selection often correlates with improved RTPs,
as competitive offerings encourage developers to enrich their
portfolios.
Different game creators maintain their own payout percentages which
can significantly impact your overall experience. Seek providers known for transparency and reliability,
such as NetEnt, Microgaming, and Evolution Gaming. These developers frequently publish their RTP figures and have a history of maintaining fair practices.
Look for games from these firms, as they often deliver better odds
compared to lesser-known counterparts.
Evaluate user reviews and industry insights to assess each provider’s track record.
Positive player feedback can indicate consistent performance, while complaints about fairness may signal red flags.
Additionally, review independent audits,
which validate game fairness and RTP accuracy, reinforcing the credibility of a given provider.
Ensure the titles you choose feature customizable rules and risk settings.
Games with multiple betting options can cater
to different playing styles, enhancing the overall experience.
Familiarize yourself with volatility levels, as they directly influence the frequency and
size of payouts. Low-volatility games yield smaller wins but more
frequently, while high-volatility options can provide substantial returns, albeit
less predictably.
Lastly, stay updated on new releases. Many established developers continuously innovate, often optimizing RTP in newer titles.
Engaging with fresh offerings may present opportunities for better returns,
making it advantageous to explore regularly launched games within reputable catalogs.
Also visit my web blog; dragon tiger apk
USACanadaPharm [url=https://usacanadapharm.shop/#]northwest canadian pharmacy[/url] usa canada pharm
canadian pharmacy com: usa canada pharm – canadian pharmacy checker
I am not sure where you’re getting your information, but great topic. I needs to spend some time learning much more or understanding more. Thanks for wonderful info I was looking for this info for my mission.
USACanadaPharm: usa canada pharm – canadian pharmacy meds reviews
canadian pharmacy price checker: legitimate canadian online pharmacies – USACanadaPharm
https://usacanadapharm.com/# usa canada pharm
totocc
buying from canadian pharmacies: USACanadaPharm – USACanadaPharm
USACanadaPharm: USACanadaPharm – pharmacy rx world canada
https://usacanadapharm.shop/# usa canada pharm
best canadian pharmacy online: usa canada pharm – usa canada pharm
pharmacy com canada: usa canada pharm – best canadian pharmacy
Hi, I do believe this is an excellent blog. I stumbledupon it 😉 I may come back yet again since I book-marked it. Money and freedom is the greatest way to change, may you be rich and continue to guide others.
olympe: olympe – olympe casino cresus
olympe casino: olympe casino en ligne – olympe casino avis
https://olympecasino.pro/# olympe
[url=https://olympecasino.pro/#]olympe casino en ligne[/url] casino olympe
casino olympe: olympe casino avis – olympe
olympe: casino olympe – olympe casino avis
casino olympe: olympe casino cresus – olympe casino en ligne
olympe casino: olympe casino avis – olympe casino avis
olympe casino avis: olympe – olympe casino
[url=https://olympecasino.pro/#]olympe casino en ligne[/url] olympe
olympe casino en ligne: olympe casino avis – olympe casino en ligne
Major thanks for the blog post.Really looking forward to read more. Really Cool.
olympe casino en ligne: casino olympe – olympe casino en ligne
I am so grateful for your article. Awesome.
olympe casino cresus: olympe casino avis – olympe
[url=https://olympecasino.pro/#]olympe[/url] olympe casino avis
olympe casino avis: olympe casino cresus – olympe casino cresus
[url=https://olympecasino.pro/#]olympe[/url] olympe casino cresus
casino olympe: olympe casino – olympe casino avis
I cannot thank you enough for the article post. Will read on…
https://olympecasino.pro/# olympe
olympe casino cresus: olympe casino – olympe casino
[url=https://olympecasino.pro/#]olympe casino cresus[/url] casino olympe
Aw, this was a very nice post. Finding the time and actual effort to make a very good article… but what can I say… I hesitate a whole lot and never seem to get nearly anything done.
olympe: olympe casino avis – olympe casino avis